一、常用命令
1 | 1. django-admin startproject mysite |
二、配置文件
1. 配置
1 | 模板文件路径: 'DIRS': [os.path.join(BASE_DIR,'templates')], |
2. 读取配置文件
 django中读取settings文件源码
django中读取settings文件源码
1 | class Settings: |
3. 补充:
根据字符串的形式,自动导入模块并使用反射找到模块中的类,执行指定的方法
1 | 步骤: |
run.py
1 | import importlib |
4. django入口
1 | from django.core.wsgi import WSGIHandler |
三、urls:路由分发
1 | URL配置(URLconf)就像Django 所支撑网站的目录。它的本质是URL模式以及要为该URL模式调用的视图函数之间的映射表;你就是以这种方式告诉Django,对于这个URL调用这段代码, |
1. 例子
1 | 1.项目.urls.py |
2. django2.0版的path
使用尖括号(<>)从url中捕获值。
捕获值中可以包含一个转化器类型(converter type),比如使用 捕获一个整数变量。若果没有转化器,将匹配任何字符串,当然也包括了 / 字符。
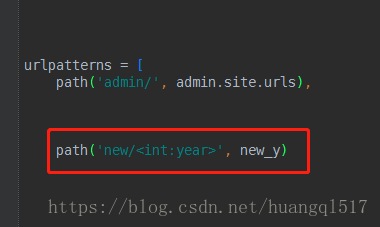
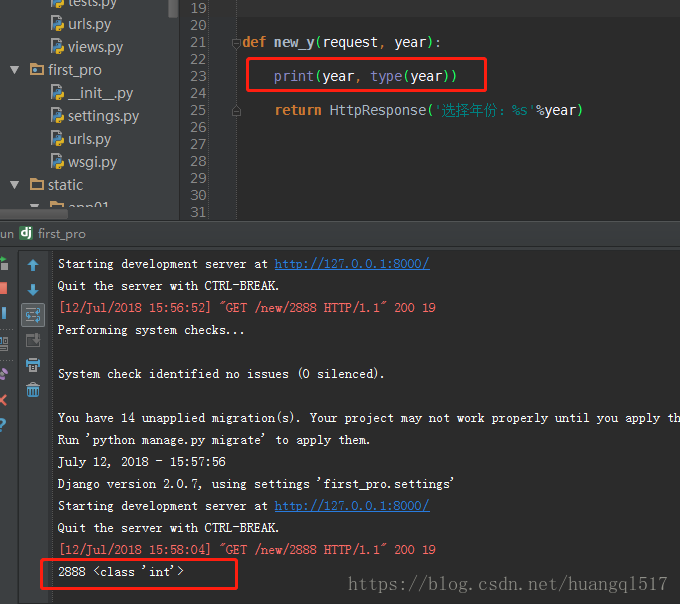
int:year这种写法直接会对取值进行转换,转换成数值类型(这个int跟python内置的int方法不一样,这是django
带的转换方法),而且指明了接收参数的名称为year,所以视图函数写法如下。
除了int转换器,还有其他的,如下

四、视图函数(views)
http请求中产生两个核心对象:
http请求:HttpRequest对象
http响应:HttpResponse对象
所在位置:django.http
之前我们用到的参数request就是HttpRequest 检测方法:isinstance(request,HttpRequest)
1. HttpRequest对象的属性和方法:
1 | # path: 请求页面的全路径,不包括域名 |
2. HttpResponse对象:
对于HttpRequest对象来说,是由django自动创建的,但是,HttpResponse对象就必须我们自己创建。每个view请求处理方法必须返回一个HttpResponse对象。
1 | HttpResponse类在django.http.HttpResponse |
五、models
model(数据库模型) —> ORM(object relation mapping)对象关系映射
一些重要概念:
1 | 1.类 -> 数据库表 class Student(): |
1.创建类
模型常用字段类型
1 | <1> CharField |
filed重要参数
1 | Field重要参数 |
多表关系及参数
1 | ForeignKey(ForeignObject) # ForeignObject(RelatedField) |
2.操作类
书籍管理表
1 | class Book(models.Model): |
学生管理表
1 | class Classes(models.Model): |
b = Book() 实例化一个类,代表创建一条记录
表与表之间的关系:
一对一:在一对多的基础上给外键加一个唯一约束
一对多:比如员工与部门,通过外键连接
多对多:书籍信息表与作者表,再加一个书籍与作者关系表,分别建立书籍与作者的外键关联
表记录的增删改查
1 | 表记录的添加 |
多表查询(一对多)
1 | 多表操作(一对多) |
多表查询(多对多)
1 | 多表查询(多对多):1.自动 2.手动 3.手动+自动 |
聚合函数和分组函数
1 | 聚合函数和分组查询 |
补充:查询相关API
1 | 补充:# 查询相关API: |
总结
1 | 总结:1.索引 |
更多请关注:https://www.cnblogs.com/zhangyafei/p/10350281.html
六、admin:后台管理工具
后台管理的特点
- 权限管理
- 少前端样式
- 快速开发
创建超级用户
1 | python manage.py createsuperuser |
admin注册
1 | # admin.py中自定制 |
补充:对django内置auth表自定义扩展
1 | from django.db import models |
settings配置
1 | AUTH_USER_MODEL = 'users.UserProfile' |
七、后台管理工具之xadmin
1. 下载安装xadmin
1 | 下载源码: https://github.com/sshwsfc/xadmin |
然后把下载的文件夹中的xadmin移到项目根目录
2. 安装依赖包
requirements.txt
1 | xlwt==1.3.0 |
安装
1 | pip install -r requirements.txt |
3. settings配置
1 | INSTALLED_APPS = [ |
4. urls配置
1 | from django.urls import path |
5. adminx注册
在每个app内新建一个adminx.py的文件
基础配置
adminx.py
1 | # -*- coding: utf-8 -*- |
