一、数据库简介
数据库:存放数据的仓库
1. sql及其规范
sql是Structured Query Language(结构化查询语言)的缩写。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持sql。
1 | (1)在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写; |
2. MYSQL常用命令
1 | -- |
1 | 1.windows启动mysql服务与停止mysql服务命令: |
\G; #\G 的作用是将查到的结构旋转90度变成纵向
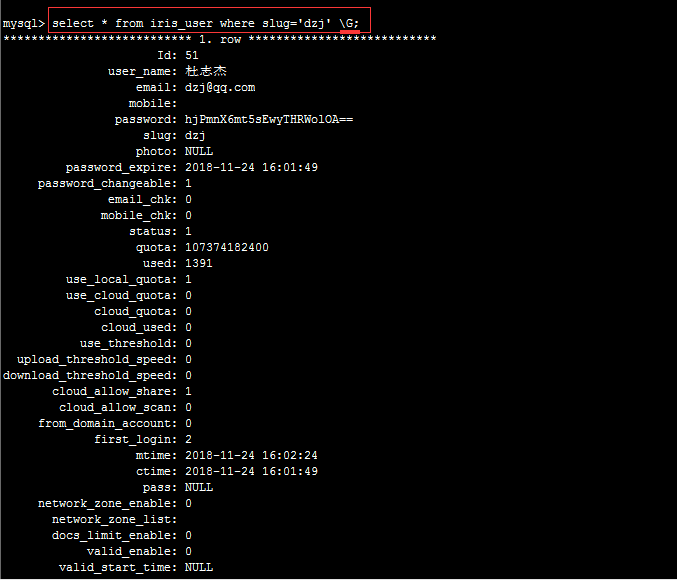
delimiter 指定分隔符
1 | DELIMITER 用于更改MySQL 命令行使用程序语句的分隔符. |
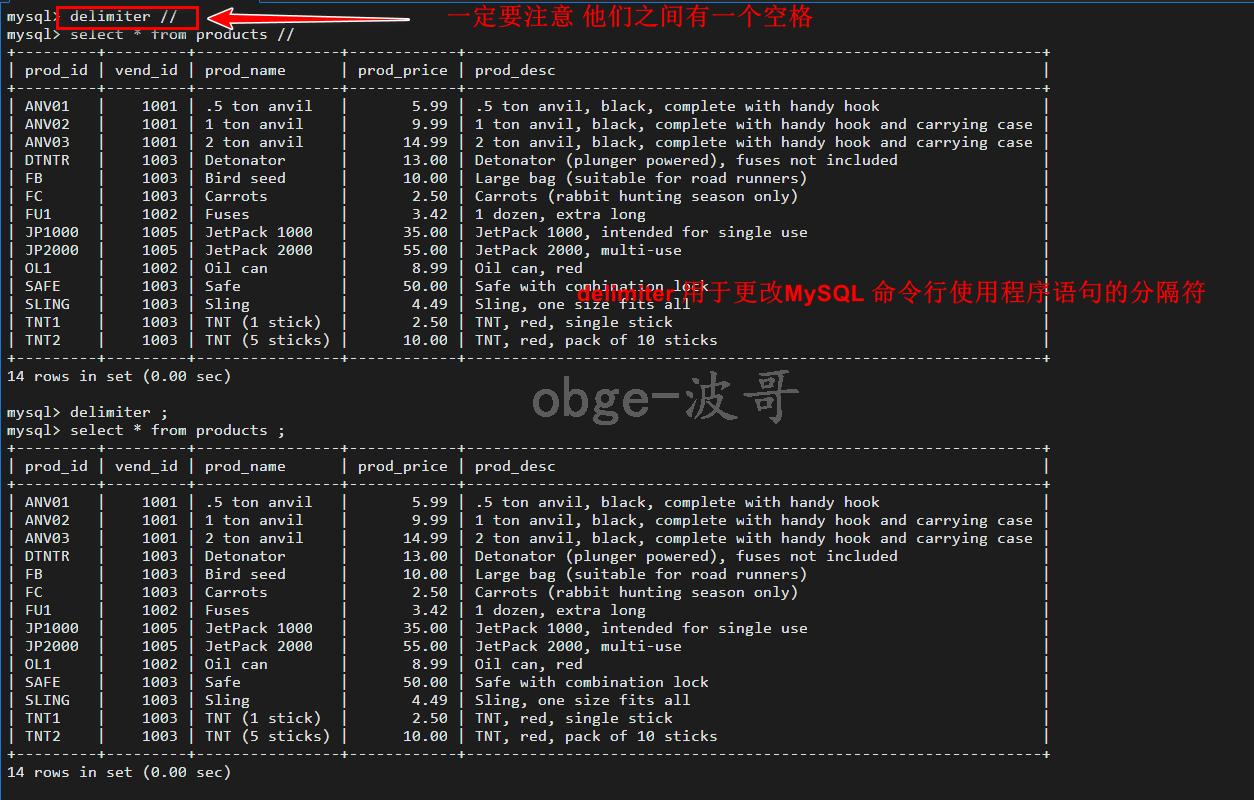
上述中,delimiter // 告诉命令行实用程序使用 // 作为新的语句结束分隔符,这样我们在使用存储过程的时候就不会出现编写不了的情况,就可以将存储过程中的内容正确传送给数据库引擎,最后在使用 delimiter ; 恢复为原来的语句分隔符。
注意:使用delimiter 声明的时候中间要有空格,
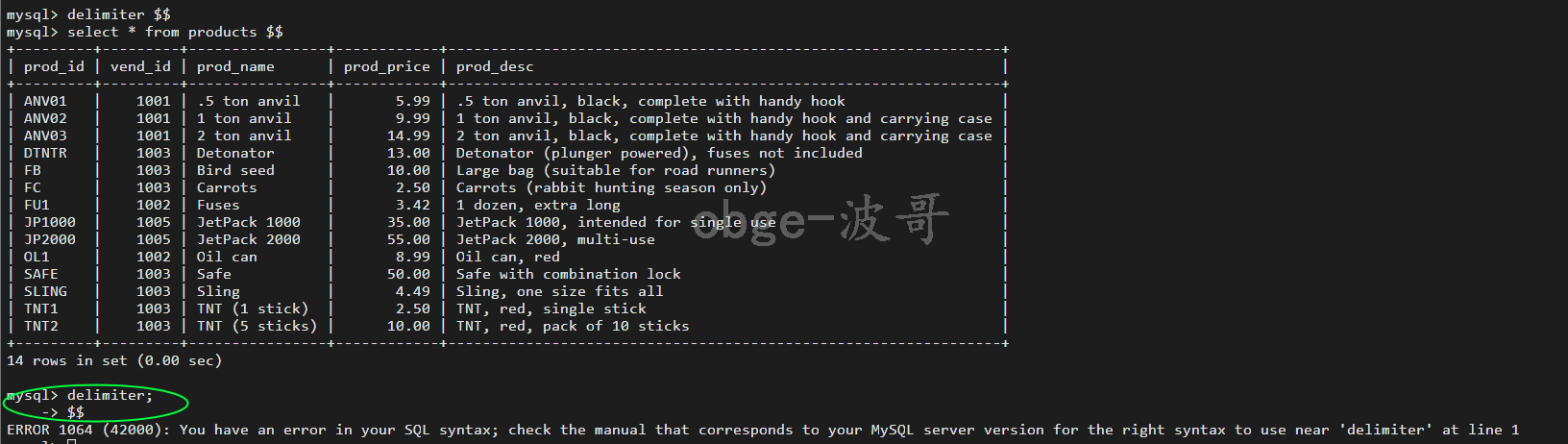
不然很难受。
最后注意:语句分隔符除了 \ 符号外,任何字符都可以用做语句分隔符
二、数据库操作(DDL)
1 | 1.查看: |
三、数据表操作
主键:非空且唯一(not null,unique)
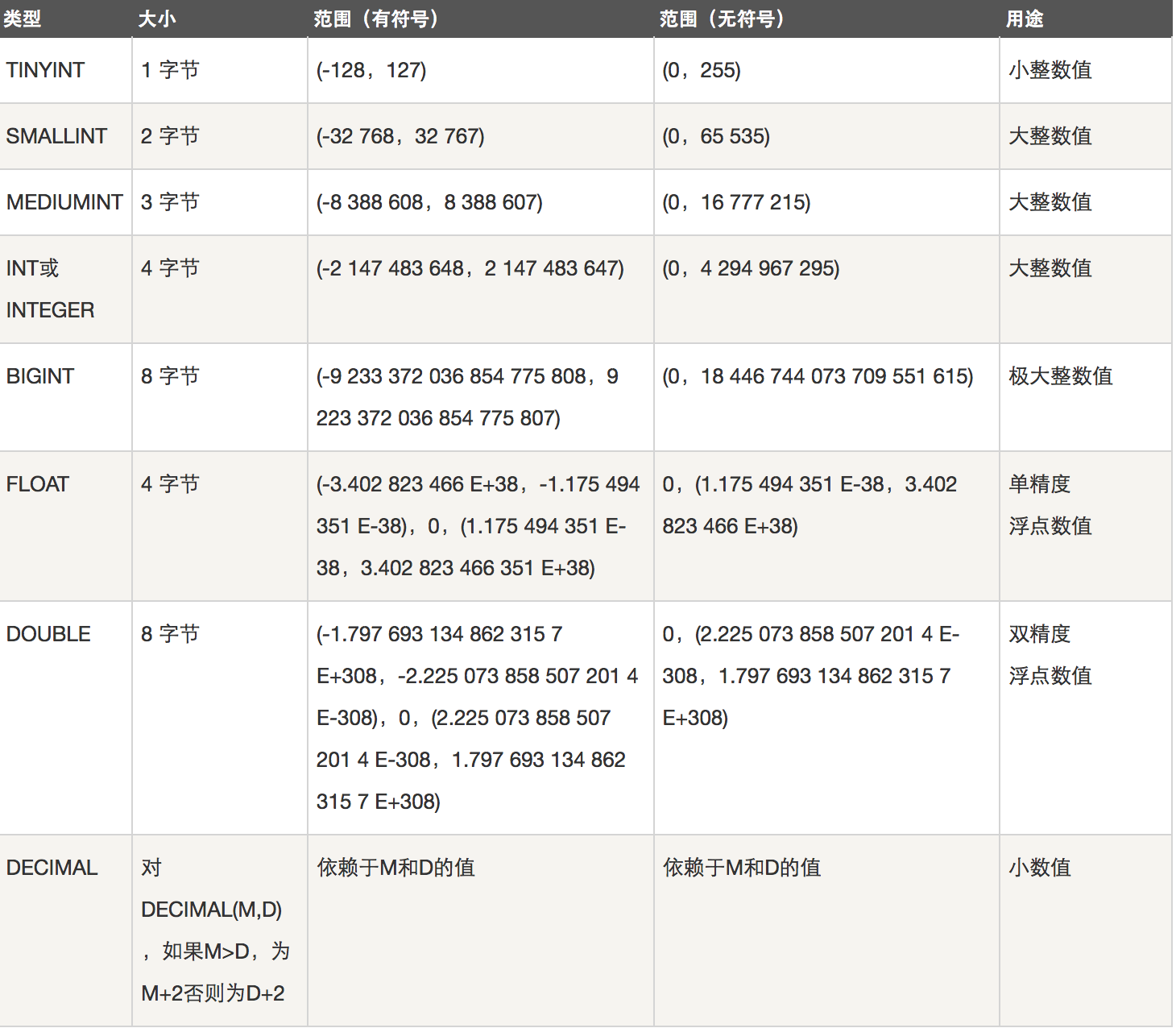
数据类型:
1. 数值类型
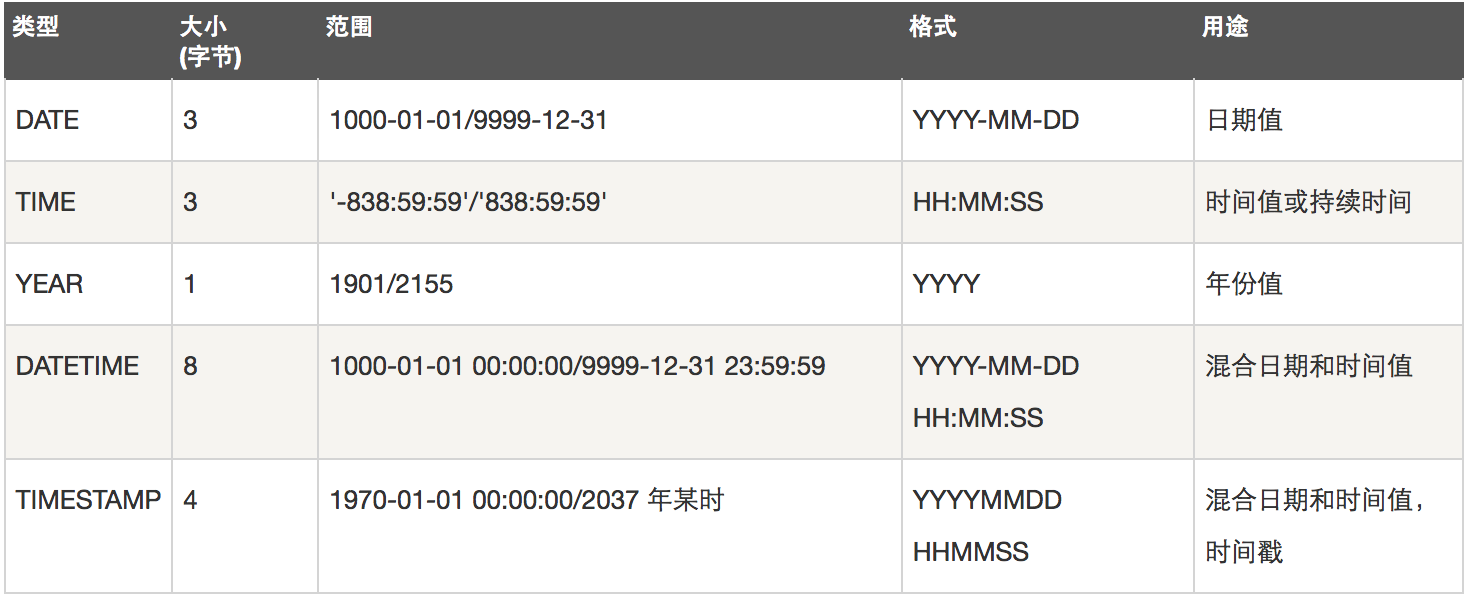
2. 日期和时间类型
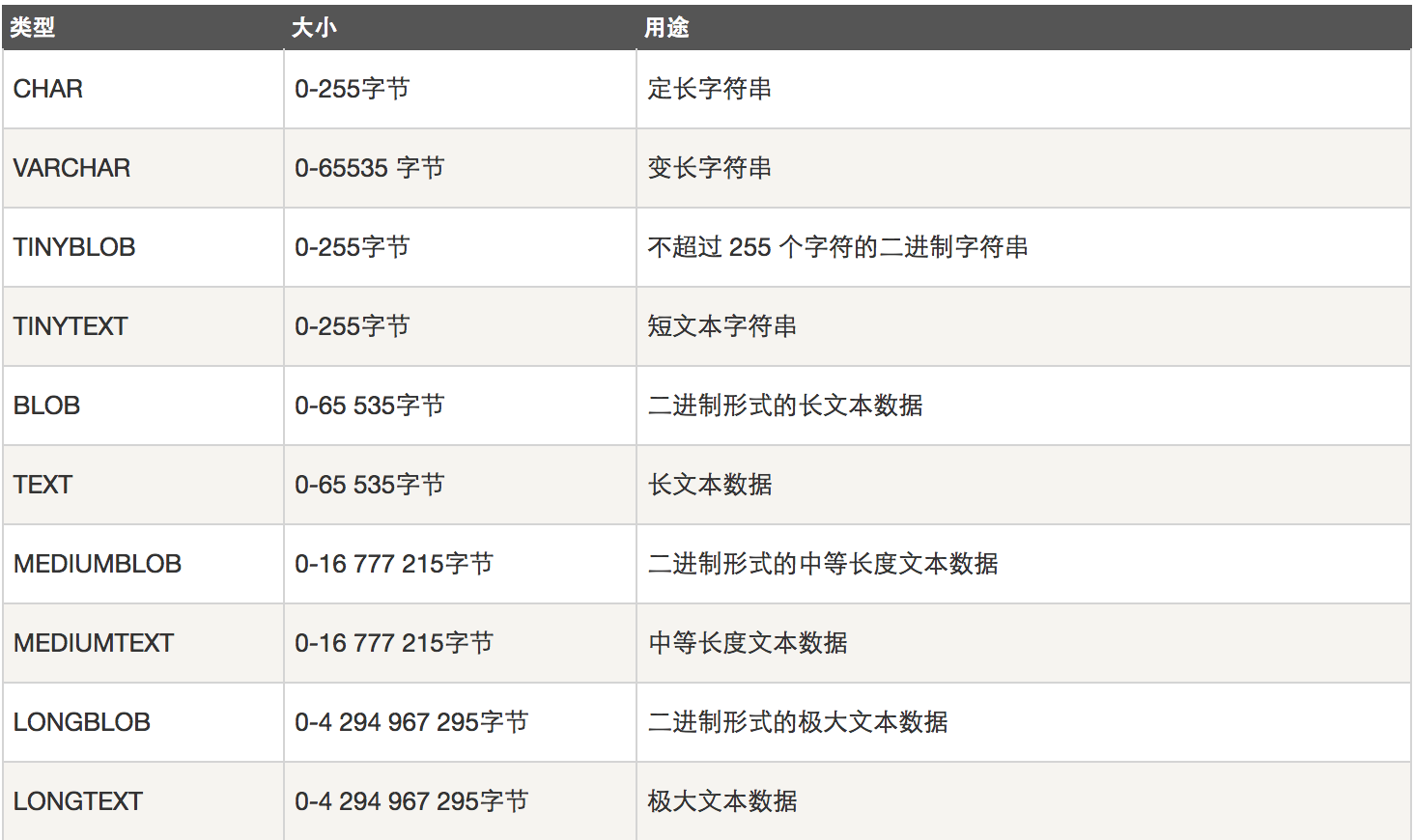
3. 字符串类型
1 | 创建表: create table tab_name( |
四、表记录操作
1 | 准备表数据 |
mysql中五种查询字句:
1 | where子句(条件查询):按照“条件表达式”指定的条件进行查询。 |
mysql查询执行顺序
1 | (7) SELECT |
增删改查示例
1 | (1)增删改查 |
五、外键约束
1 | 创建外键 |
六、连表查询
1、内联接(典型的联接运算,使用像 = 或 <> 之类的比较运算符)。包括相等联接和自然联接。
- inner join(等值连接) 只返回两个表中联结字段相等的行
2、外联接。外联接可以是左向外联接、右向外联接或完整外部联接。
- left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
- right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
- full join(全联接) 返回包括右表中的所有记录和左表中所有的记录
3、交叉联接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积。
FROM 子句中的表或视图可通过内联接或完整外部联接按任意顺序指定;但是,用左或右向外联接指定表或视图时,表或视图的顺序很重要。有关使用左或右向外联接排列表的更多信息,请参见使用外联接。
内外连接查询示例
1 | mysql> use flask_code |
交叉连接示例
1 | mysql> select * from record; |
七、联合查询
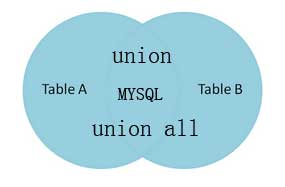
1. UNION和UNION ALL的作用和语法
UNION 用于合并两个或多个 SELECT 语句的结果集,并消去表中任何重复行。
UNION 内部的 SELECT 语句必须拥有相同数量的列,列也必须拥有相似的数据类型。
同时,每条 SELECT 语句中的列的顺序必须相同.
SQL UNION 语法:
sql脚本代码如下:
1 | 1 SELECT column_name FROM table1 |
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
当 ALL 随 UNION 一起使用时(即 UNION ALL),不消除重复行
SQL UNION ALL 语法
sql脚本代码如下:
1 | 1 SELECT column_name FROM table1 |
注释:另外,UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
注意:1、UNION 结果集中的列名总是等于第一个 SELECT 语句中的列名
2、UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同
2. union的用法及注意事项
union:联合的意思,即把两次或多次查询结果合并起来。
要求:两次查询的列数必须一致
推荐:列的类型可以不一样,但推荐查询的每一列,想对应的类型以一样
可以来自多张表的数据:多次sql语句取出的列名可以不一致,此时以第一个sql语句的列名为准。
如果不同的语句中取出的行,有完全相同(这里表示的是每个列的值都相同),那么union会将相同的行合并,最终只保留一行。也可以这样理解,union会去掉重复的行。
如果不想去掉重复的行,可以使用union all。
如果子句中有order by,limit,需用括号()包起来。推荐放到所有子句之后,即对最终合并的结果来排序或筛选。
如:sql脚本代码如下:
1 | 1 (select * from a order by id) union (select * from b order id); |
在子句中,order by 需要配合limit使用才有意义。如果不配合limit使用,会被语法分析器优化分析时去除。
3. 学习例子
联合查询示例
1 | # 选择数据库 |
八、limit分页
Limit子句可以被用于强制 SELECT 语句返回指定的记录数。Limit接受一个或两个数字参数。参数必须是一个整数常量。如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
1 | //初始记录行的偏移量是 0(而不是 1): |
Limit的效率高?
1 | 常说的Limit的执行效率高,是对于一种特定条件下来说的:即数据库的数量很大,但是只需要查询一部分数据的情况。 |
Limit的效率低?
1 | 在一种情况下,使用limit效率低,那就是:只使用limit来查询语句,并且偏移量特别大的情况 |
附录:OFFSET
1 | 为了与 PostgreSQL 兼容,MySQL 也支持句法: LIMIT # OFFSET #。 |
limit查询实例
1 | mysql> select * from proxy limit 5; |
九、数据库引擎
1 | Mysql引擎种类:innodb,mysaim |
- innodb:支持事务,锁(支持行锁和表锁)
- mysaim:不支持事务。锁(支持表锁),优势速度快
1 | Innodb引擎 |
1 | 终端1: |
加锁示例
1 | mysql> begin; |
一般情况下,mysql会默认提供多种存储引擎,你可以通过下面的查看:
mysql查看存储引擎
1 | mysql> show engines; |
mysql加锁(行锁和表锁)示例
1 | mysql> begin; |
补充:
执行计划
1 | explain select * from tb; |
mysql常用语法命令及函数
1 | #创建数据库# create database 数据库名; |
