Hello,小伙子们,小姑娘们,我又要出新教程了!本次教程为Python爬虫实战:高清图片下载,主要针对刚学完Python基础的同学,或者想学习爬虫方向的年轻人,很合适作为爬虫入们教程,难度虽然不高,但小项目仍然蕴含有大智慧。
项目演示
演示视频:https://www.bilibili.com/video/BV14i4y1N7pP/
项目代码:爬虫实战:高清图片下载
本教程将用到的知识点有:
requests的使用lxml库解析htmljson数据解析图片数据存储请求过滤进度条打印多线程提速其他
项目一:NET牛人
一、目标网站分析
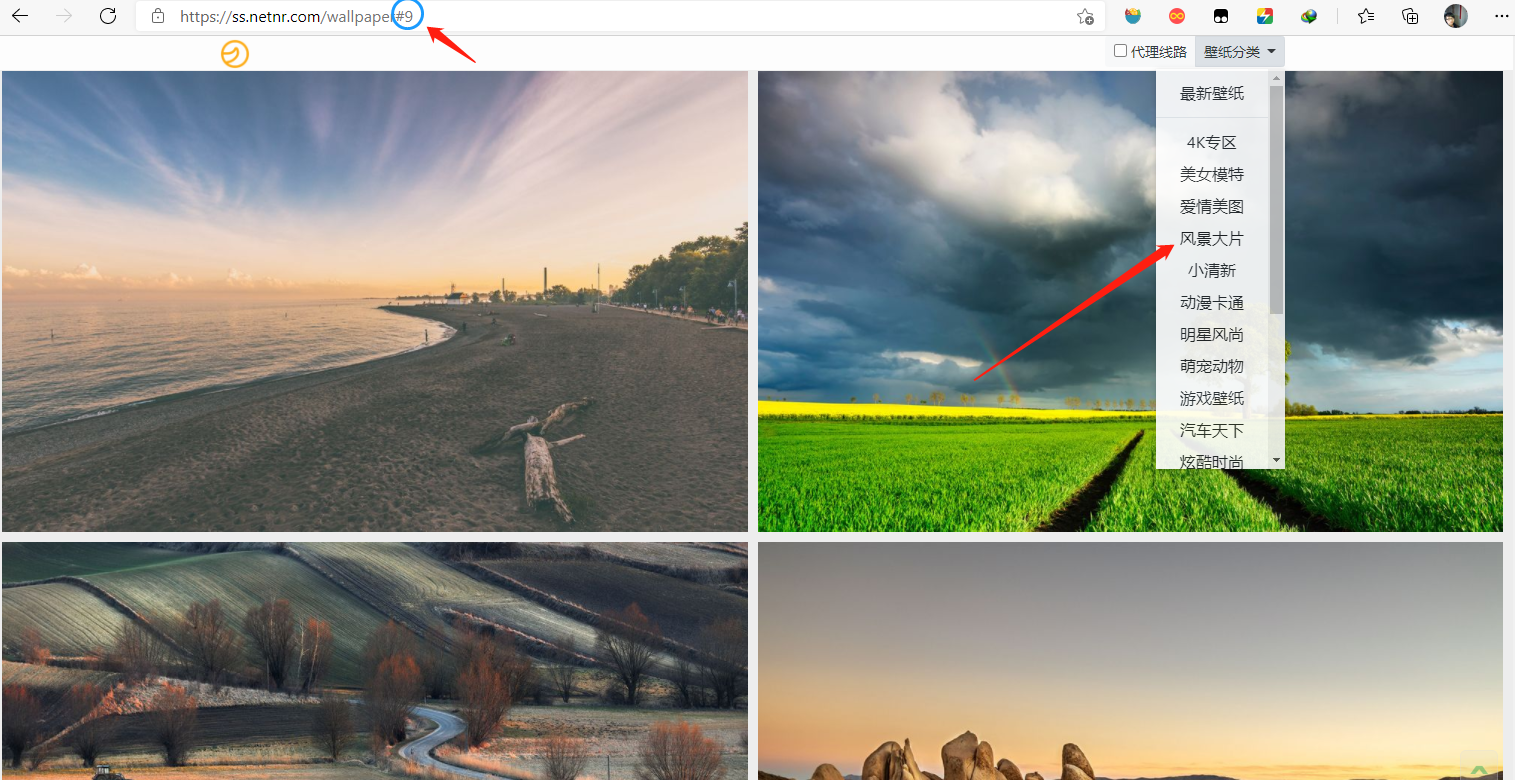
网址:https://ss.netnr.com/wallpaper
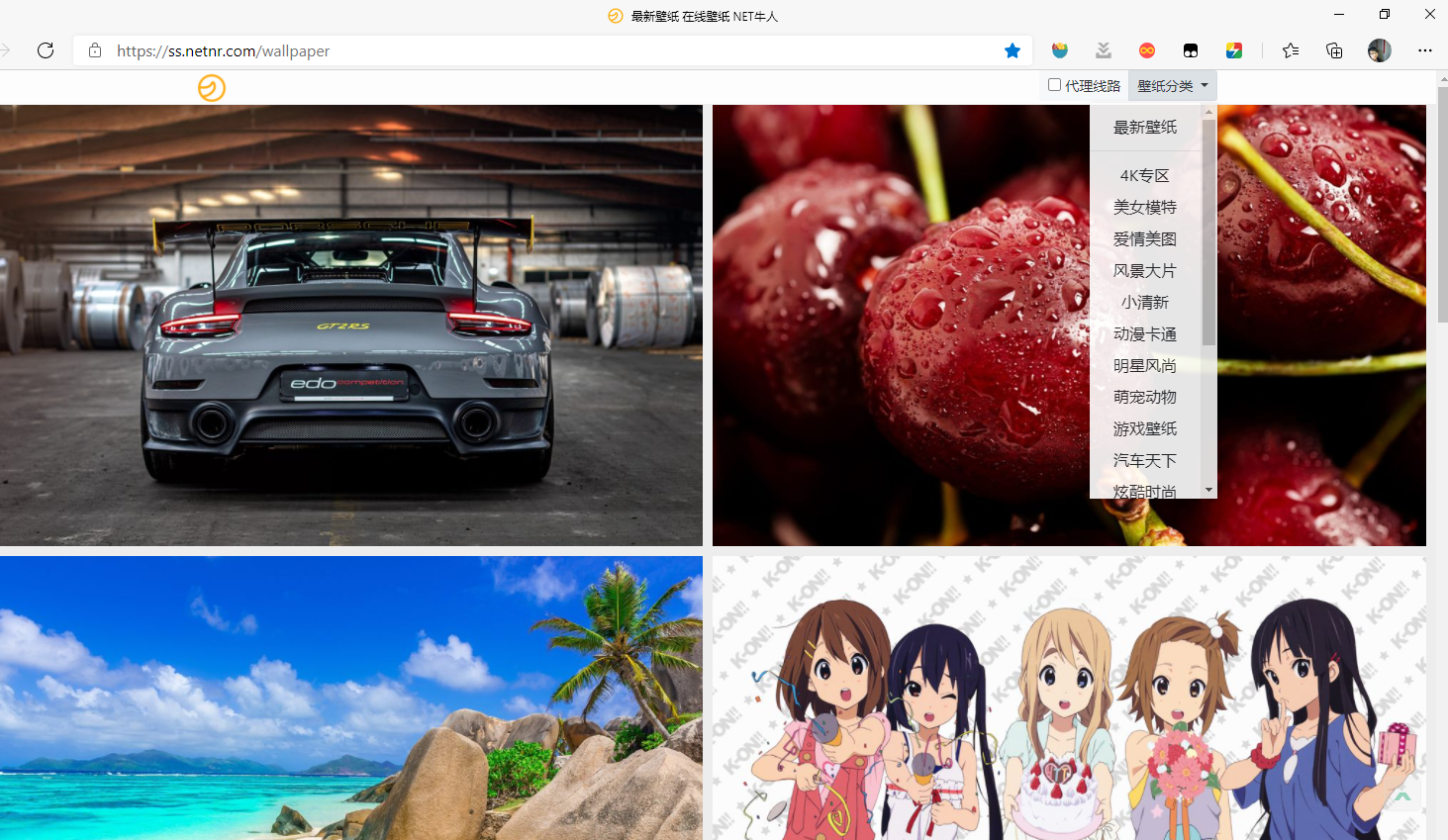
该网站提供了各种格式的高清壁纸,用户可以根据自己的需要选择相应格式下载,鼠标向下拉会自动刷新获取更多壁纸,该网站有4K专区、美女模特、风景大片等18种壁纸分类,默认为最新壁纸。
我们的目标就是:使用Python自动化下载该网站的高清壁纸,可以指定类别和下载数量。当然,有兴趣的伙伴也可以指定壁纸分辨率,本教程将按照该网站所提供壁纸的最高分辨率进行下载。
二、网络请求分析
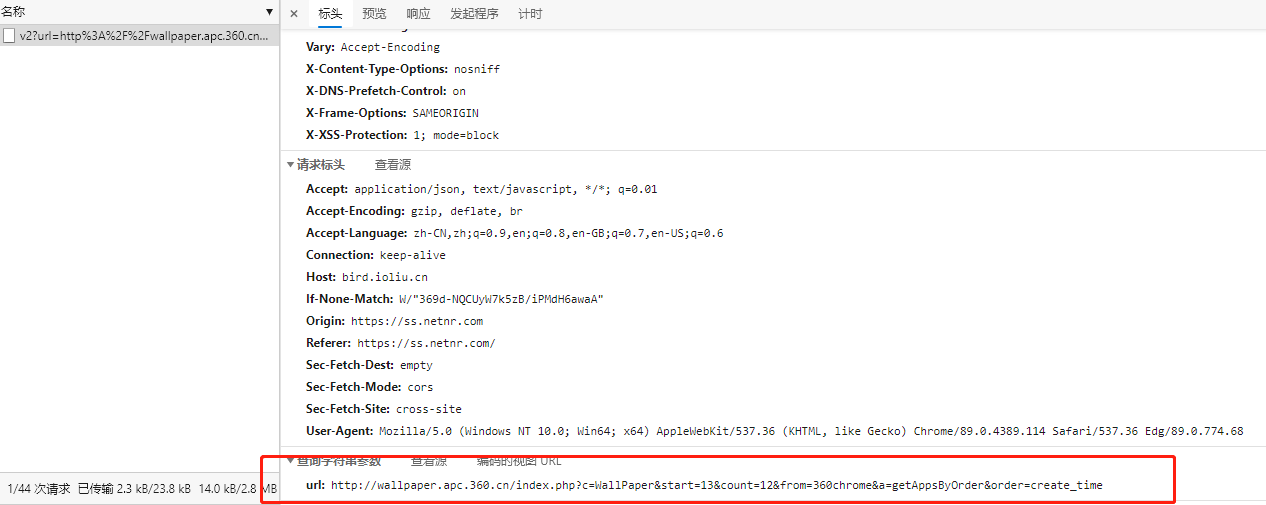
右键点击 - “检查 - 网络”,刷新页面,观察请求变化,结果在XHR-ajax请求中发现了每次获取新数据都会发送的请求,
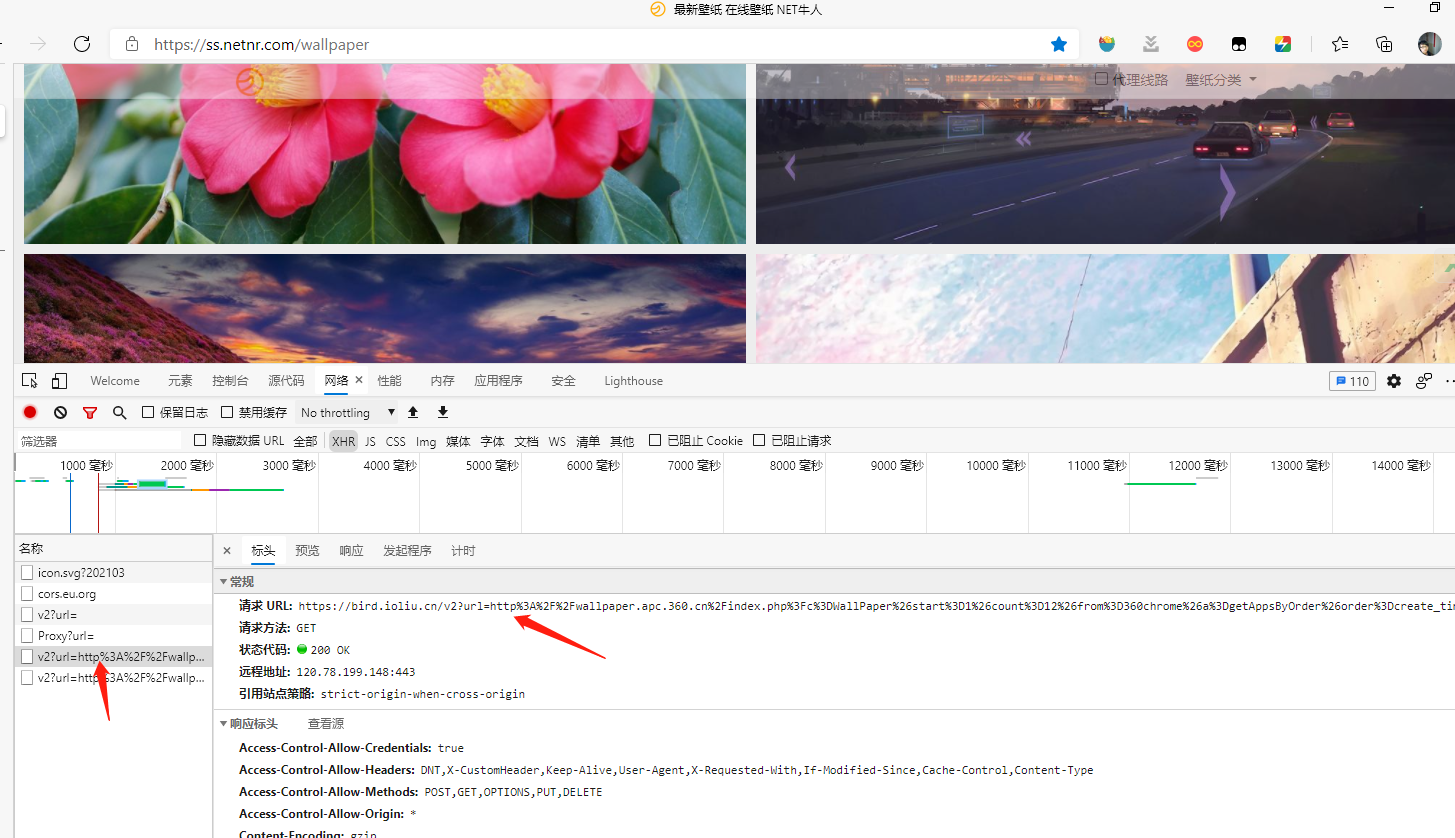
我们再观察一下它的返回信息,果然就是我们需要的图片信息。返回数据为json格式,data中包含了12个元素,每个元素都是一张图片的信息,其中包含可以获取的所有分辨率的图片地址,默认url为最高分辨率,我们观察到,还有两个重要的元素,id和tag, id是唯一标示,tag是图片的描述,这两个值我们在给图片命名的时候会用到。
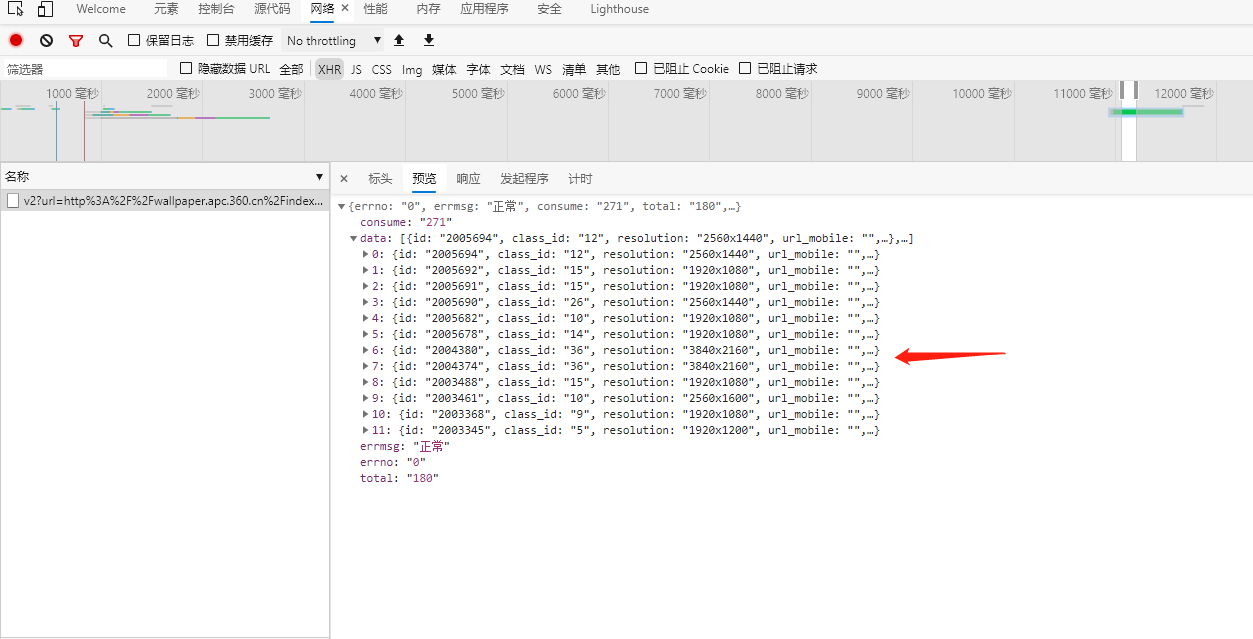
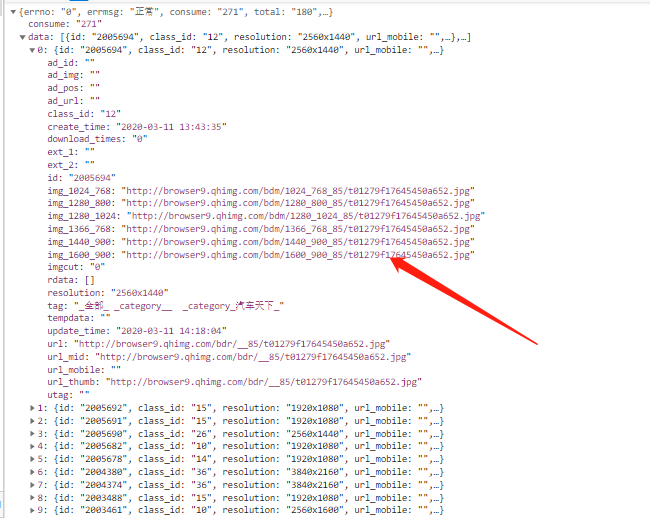
我们再来观察一下请求信息,发现请求url为https://bird.ioliu.cn/v2,GET请求,每会携带一个参数url,http://wallpaper.apc.360.cn/index.php?c=WallPaper&start=13&count=12&from=360chrome&a=getAppsByOrder&order=create_time,其中参数start和count分别是起始位置和数量的意思,另外,如果没有选择分类,默认是按时间排序,如果选择分类,http://wallpaper.apc.360.cn/index.php?c=WallPaper&start=1&count=12&from=360chrome&a=getAppsByCategory&cid=36,将会有一个参数cid,值为分类id。我们在页面右上角可以选择壁纸分类,当我们点击分类的时候,页面url对应的#id都会发生变化。
总结:有三个重要的参数,start:起始位置,count:请求数量,cid:分类ID, 若要获取最新壁纸,order=create_time
经过上述网络请求分析,可以看出本次任务请求构造和逻辑较简单,那么接下来我们将去实现它。
三、初步实现
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import requests
url = 'https://bird.ioliu.cn/v2'
start = 1
count = 12
params = {'url': f'http://wallpaper.apc.360.cn/index.php?c=WallPaper&start={start}&count={count}&from=360chrome&a=getAppsByOrder&order=create_time'}
response = requests.get(url=url, params=params)
result = response.json()
for image_info in result['data']:
uid = image_info['id']
image_url = image_info['url']
tags = image_info['tag'].replace('_category_', '').replace('_全部_', '').strip('_ ').replace(' ', '')
size = image_info['resolution'].replace('x', '_')
print(image_url, tags, size, uid)运行结果
1
2
3
4
5
6
7
8
9
10
11
12
13λ python spider.py
http://browser9.qhimg.com/bdr/__85/t01753453b660de14e9.jpg 汽车天下 1920_1080 2008041
http://browser9.qhimg.com/bdr/__85/t01bbd94b90e850d1d3.jpg 动感水果_车厘子_小清新 1920_1080 2008033
http://browser9.qhimg.com/bdr/__85/t019fd908f724f51900.jpg 海洋天堂_沙滩_风景大片 1920_1080 2008032
http://browser9.qhimg.com/bdr/__85/t010448c46c1ecf7cab.jpg 卡通人物_动漫卡通 1920_1200 2007786
http://browser9.qhimg.com/bdr/__85/t0183def7a3a7924215.jpg 自然风光_瀑布_风景大片 1920_1080 2007276
http://browser9.qhimg.com/bdr/__85/t016ad88ddaf2ae2d92.jpg 雪山_天空__风景大片 2560_1440 2007035
http://browser9.qhimg.com/bdr/__85/t0179b947962a684673.jpg 娇艳欲滴_茶花_小清新 1920_1080 2007033
http://browser9.qhimg.com/bdr/__85/t01cd97ec806b712059.jpg 未来城市_航天飞机_4K专区 3840_2160 2007028
http://browser9.qhimg.com/bdr/__85/t018160b069da5cac0d.jpg 落日余晖_花海_风景大片 1920_1080 2007013
http://browser9.qhimg.com/bdr/__85/t013a4ed4683039d101.jpg 自行车_街道_动漫卡通 1920_1080 2007011
http://browser9.qhimg.com/bdr/__85/t01a78941bc25ae2cf9.jpg 兔子_萌宠动物 1920_1080 2005698
http://browser9.qhimg.com/bdr/__85/t01b85e62ab512342e5.jpg 落日余晖_秧田_风景大片 1920_1080 2005696按照我们之前的分析进行代码编写,运行之后发现整个流程没有任何问题,我们成功获取到了图片的id、url、tags和size。核心步骤实现了之后,我们就要开始完善细节部分了。
四、自定义参数和图片存储
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42import os
import requests
image_type_info = {
0: '最新壁纸', 6: '美女模特', 30: '爱情美图', 9: '风景大片',
36: '4K专区', 15: '小清新', 26: '动漫卡通', 11: '明星风尚',
14: '萌宠动物', 5: '游戏壁纸', 12: '汽车天下', 10: '炫酷时尚',
29: '月历壁纸', 7: '景视剧照', 35: '文字控', 13: '节日美图',
22: '军事天地', 16: '劲爆体育', 18: 'BABY秀'
}
def main(start: int, count: int, image_type: int):
url = 'https://bird.ioliu.cn/v2'
if image_type == 0:
params = {'url': f'http://wallpaper.apc.360.cn/index.php?c=WallPaper&start={start}&count={count}&from=360chrome&a=getAppsByOrder&order=create_time'}
else:
params = {'url': f'http://wallpaper.apc.360.cn/index.php?c=WallPaper&start={start}&count={count}&from=360chrome&a=getAppsByCategory&cid={image_type}'}
# 图片文件夹分类
image_type_desc = image_type_info[image_type]
if not os.path.exists(f'images/{image_type_desc}'):
os.makedirs(f'images/{image_type_desc}')
# 发送请求
response = requests.get(url=url, params=params)
result = response.json()
for image_info in result['data']:
uid = image_info['id']
image_url = image_info['url']
tags = image_info['tag'].replace('_category_', '').replace('_全部_', '').strip('_ ').replace(' ', '')
size = image_info['resolution'].replace('x', '_')
filepath = f'images/{image_type_info[image_type]}/{tags}_{uid}_{size}.jpg'
response = requests.get(image_url)
with open(filepath, mode='wb') as f:
f.write(response.content)
print(f'{image_url} {filepath} 下载成功')
if __name__ == '__main__':
main(start=1, count=12, image_type=0)运行结果
1
2
3
4
5
6
7
8
9
10
11
12
13λ python spider.py
http://browser9.qhimg.com/bdr/__85/t01753453b660de14e9.jpg images/最新壁纸/汽车天下_2008041_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t01bbd94b90e850d1d3.jpg images/最新壁纸/动感水果_车厘子_小清新_2008033_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t019fd908f724f51900.jpg images/最新壁纸/海洋天堂_沙滩_风景大片_2008032_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t010448c46c1ecf7cab.jpg images/最新壁纸/卡通人物_动漫卡通_2007786_1920_1200.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t0183def7a3a7924215.jpg images/最新壁纸/自然风光_瀑布_风景大片_2007276_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t016ad88ddaf2ae2d92.jpg images/最新壁纸/雪山_天空__风景大片_2007035_2560_1440.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t0179b947962a684673.jpg images/最新壁纸/娇艳欲滴_茶花_小清新_2007033_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t01cd97ec806b712059.jpg images/最新壁纸/未来城市_航天飞机_4K专区_2007028_3840_2160.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t018160b069da5cac0d.jpg images/最新壁纸/落日余晖_花海_风景大片_2007013_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t013a4ed4683039d101.jpg images/最新壁纸/自行车_街道_动漫卡通_2007011_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t01a78941bc25ae2cf9.jpg images/最新壁纸/兔子_萌宠动物_2005698_1920_1080.jpg 下载成功
http://browser9.qhimg.com/bdr/__85/t01b85e62ab512342e5.jpg images/最新壁纸/落日余晖_秧田_风景大片_2005696_1920_1080.jpg 下载成功当前目录下会生成images和最新壁纸两个文件夹,里面有刚下载的12张图片。
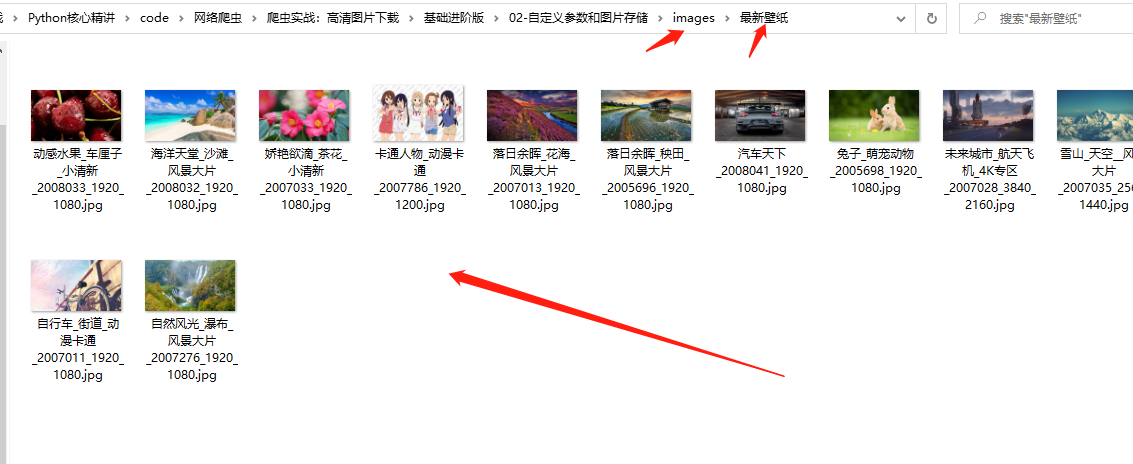
至此,我们已经实现了项目的核心下载功能,但,还不够完善。
五、功能完善
1. 用户提示信息
1 | from prettytable import PrettyTable |
2. 获取用户输入
1 | while True: |
3. 添加下载进度条
1 | def main(image_type: int, start: int = 1, count: int = 50): |
4. 代码整合
1 | import os |
运行结果
1 | +-------+-----------+-------+-----------+ |
六、项目优化
1. 实现过滤功能
1 | def init_history_file(): |
第一次运行
1 | +-------+-----------+-------+-----------+ |
查看图片文件夹
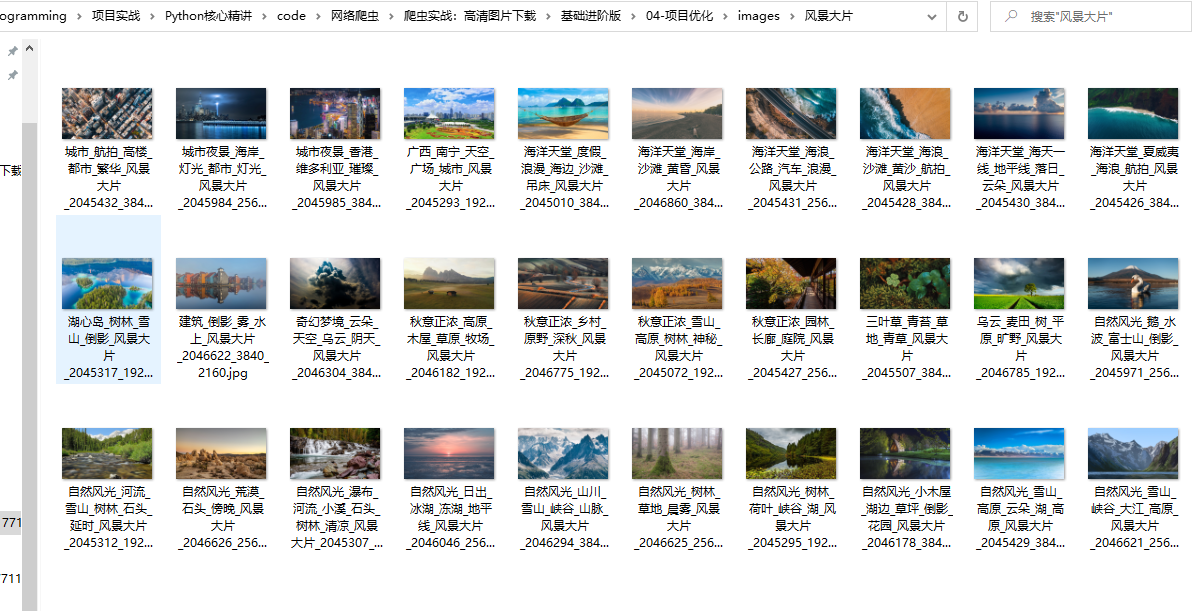
当前目录下生成了一个history.txt文件,文件内容
1 | images/风景大片/海洋天堂_海岸_沙滩_黄昏_风景大片_2046860_3840_2160.jpg |
第二次运行
1 | +-------+-----------+-------+-----------+ |
2. 多线程下载加速
1 | from concurrent.futures import ProcessPoolExecutor |
运行代码
第一次运行
1 | +-------+-----------+-------+-----------+ |
第二次
1 | +-------+-----------+-------+-----------+ |
3. 为打印输出添加色彩
utils.py
1 | class Foreground: |
spider.py
1 | import os |
运行结果
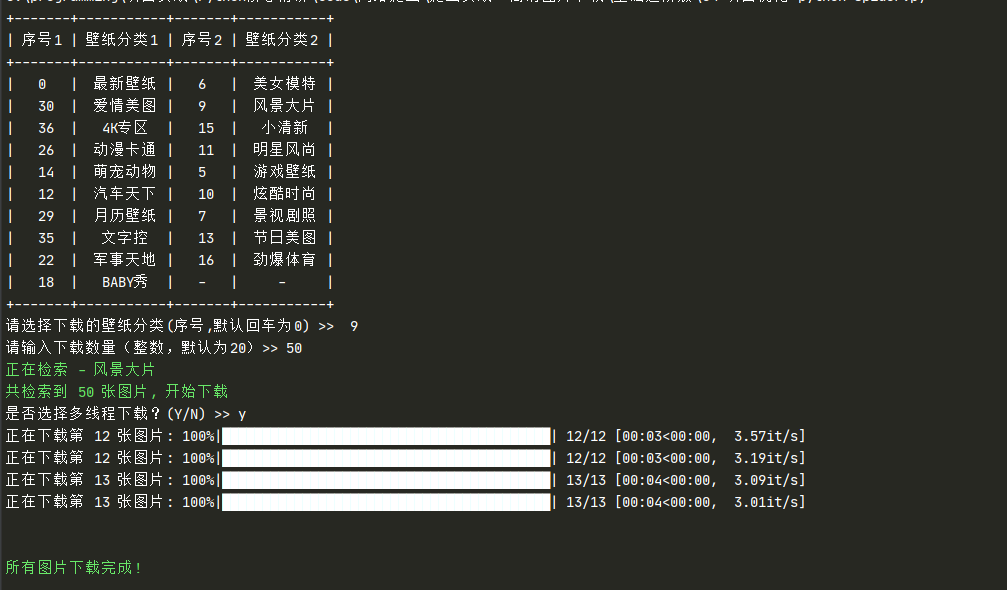
运行代码演示
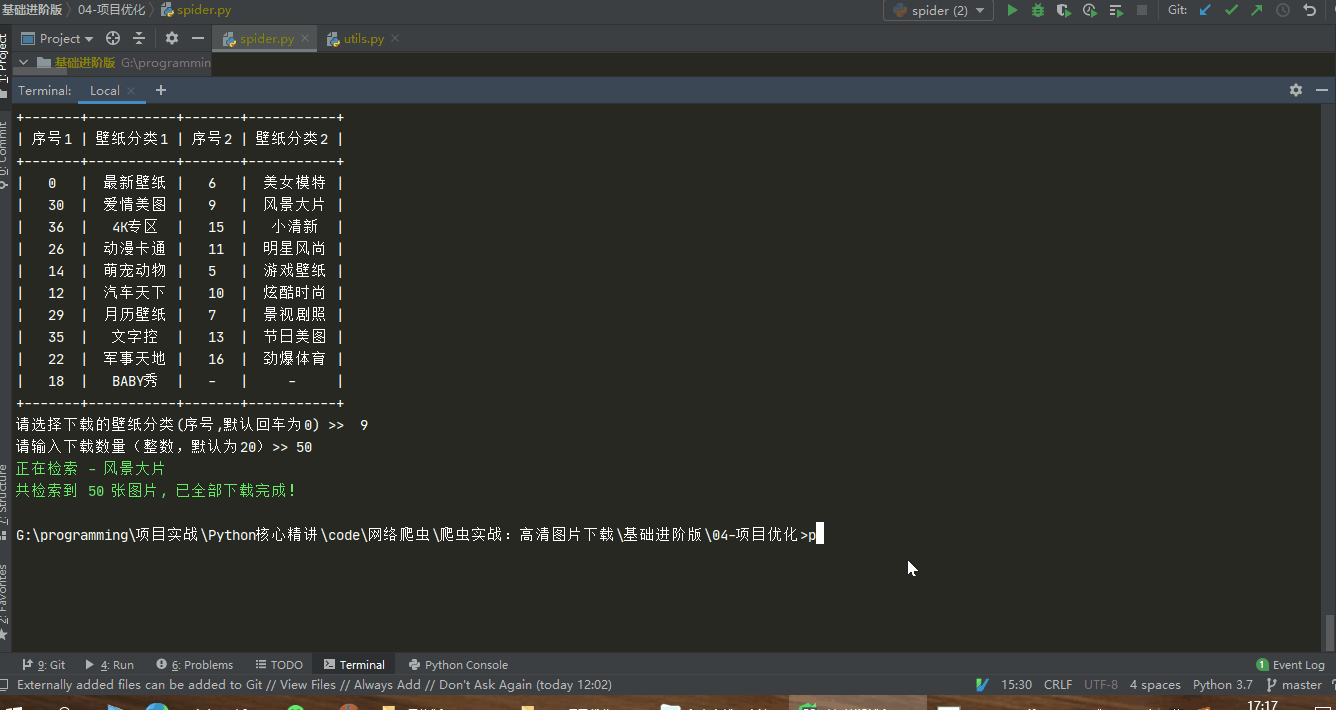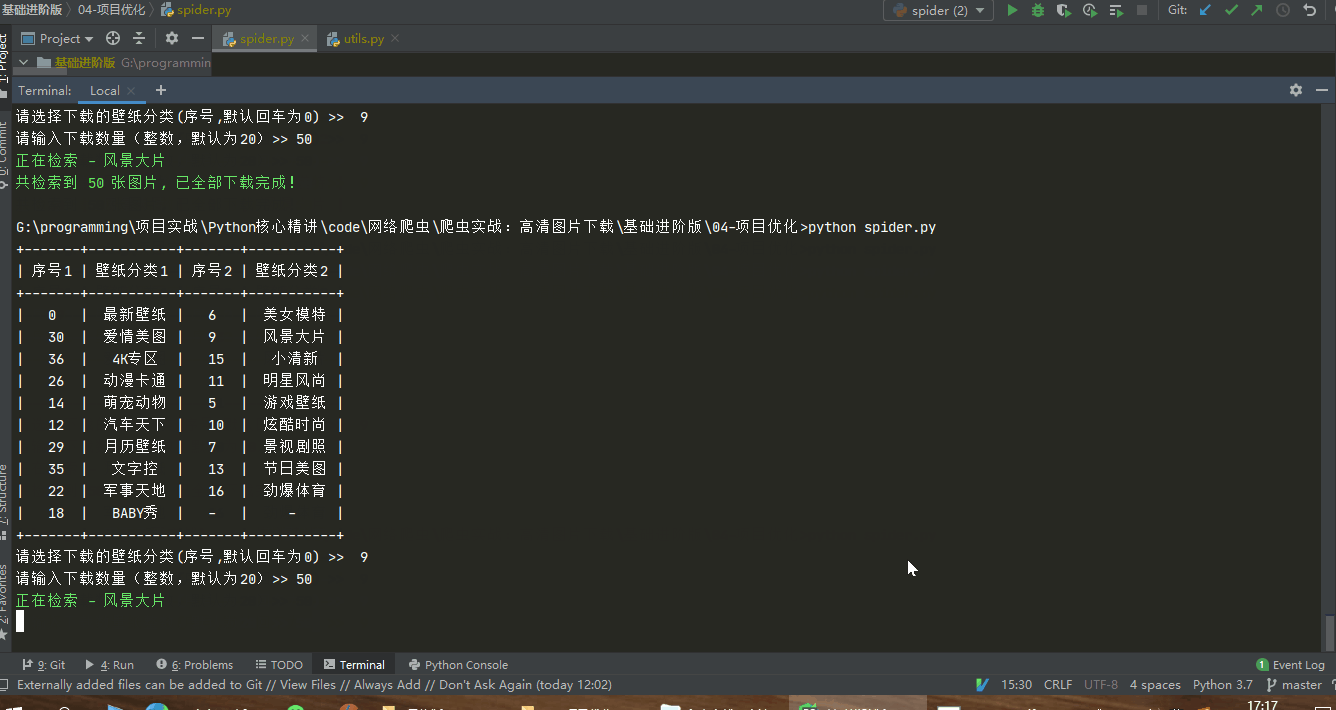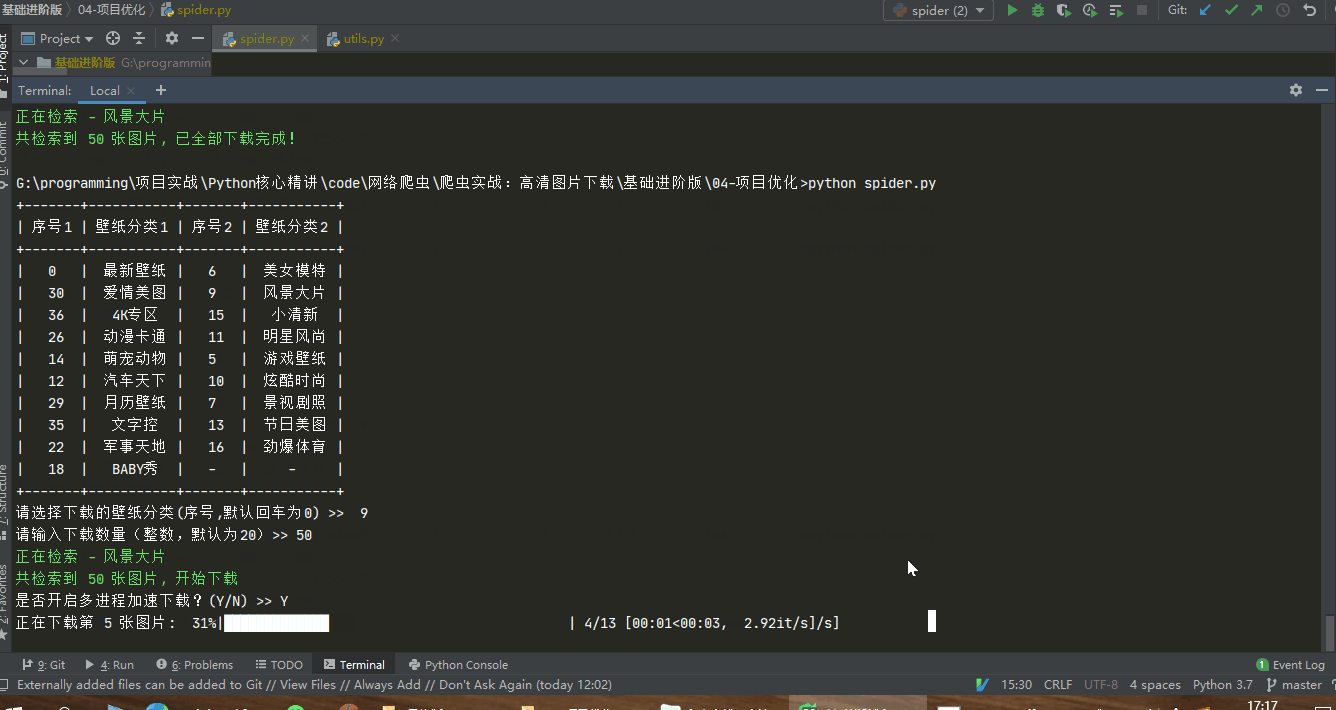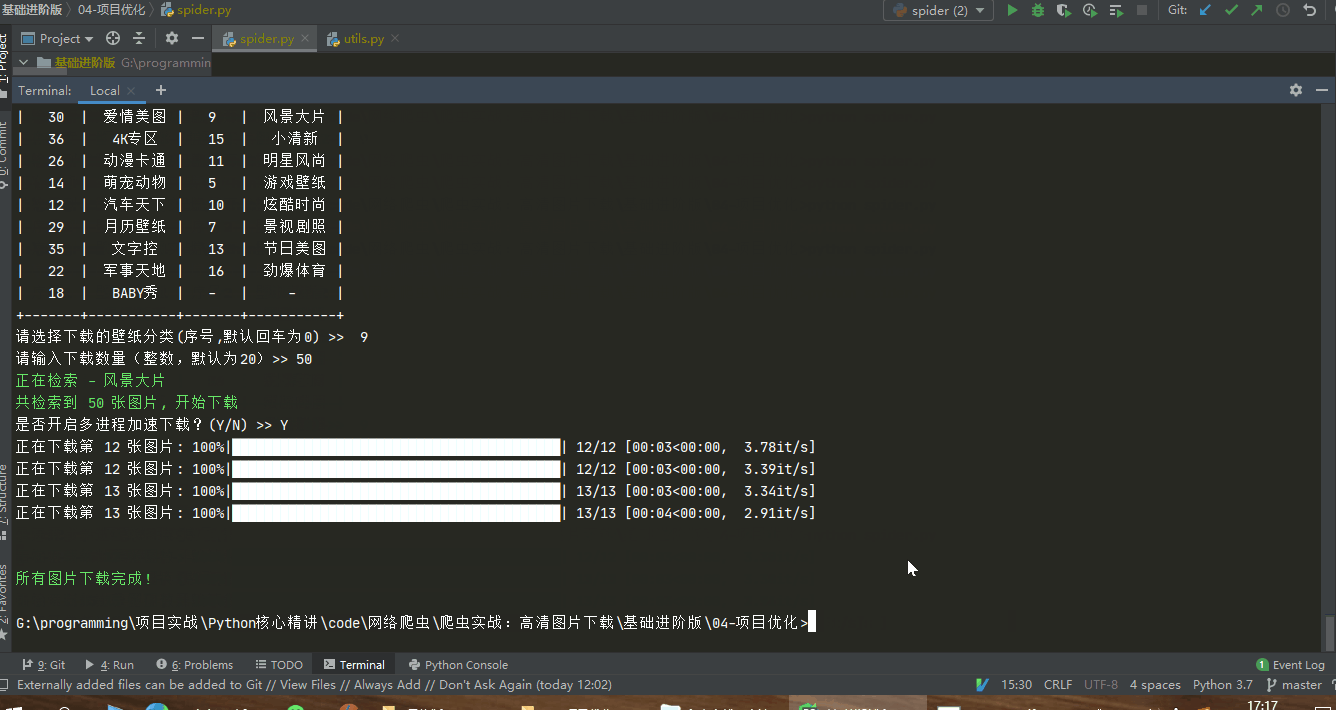
4. 面向对象
以上代码均是基于函数式编程书写的,虽然目前代码总体只有150行左右,但是能感觉到随着功能的扩展,模块之后的位置和关联还是有些乱的,所以有必要将其改写成面向对象的形式了。代码我已经写好,有兴趣的伙伴可以进行学习:爬虫实战:高清图片下载
项目二:彼岸图网
一、目标网站分析
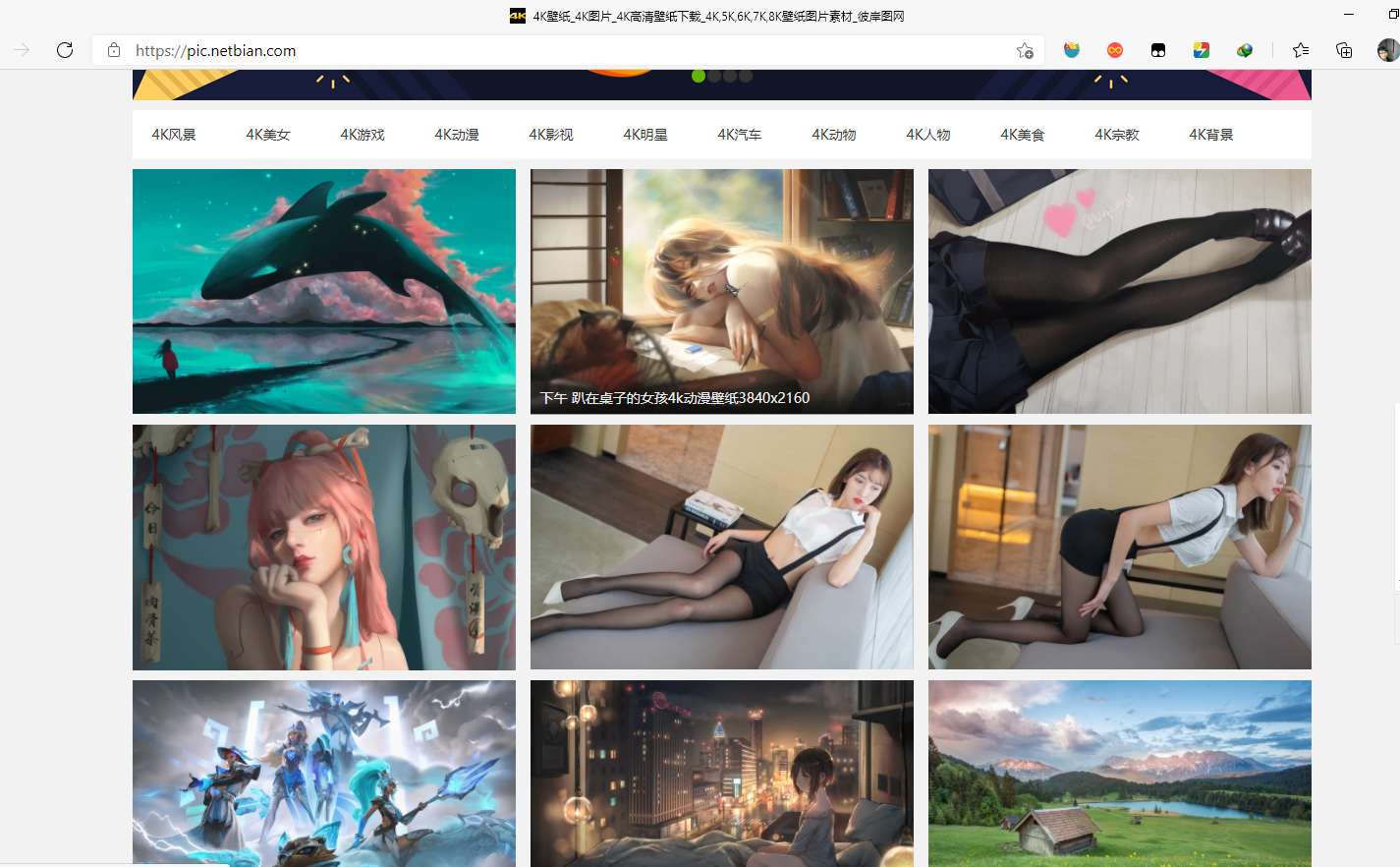
该网站提供了4K风景、4K美女等12种壁纸类别,用户可以选择任一类别的图片进行查看和下载。点击某一分类可以发现,浏览器地址栏的url追加了对应的分类路径,观察分类下的图片,鼠标右键可以直接下载图片,下载之后发现分辨率较低,不太清晰,我们点击进去任意一张图片,查看详细内容页面,发现详细页面的图片相较于检索页分辨率高了不少,另外还可以下载原图,不过原图要登录和收费,所以暂时我们不考虑,详细页面显示图片的分辨率已经相对很好了。
我们的目标就是自动化获取和下载详细页面的图片。
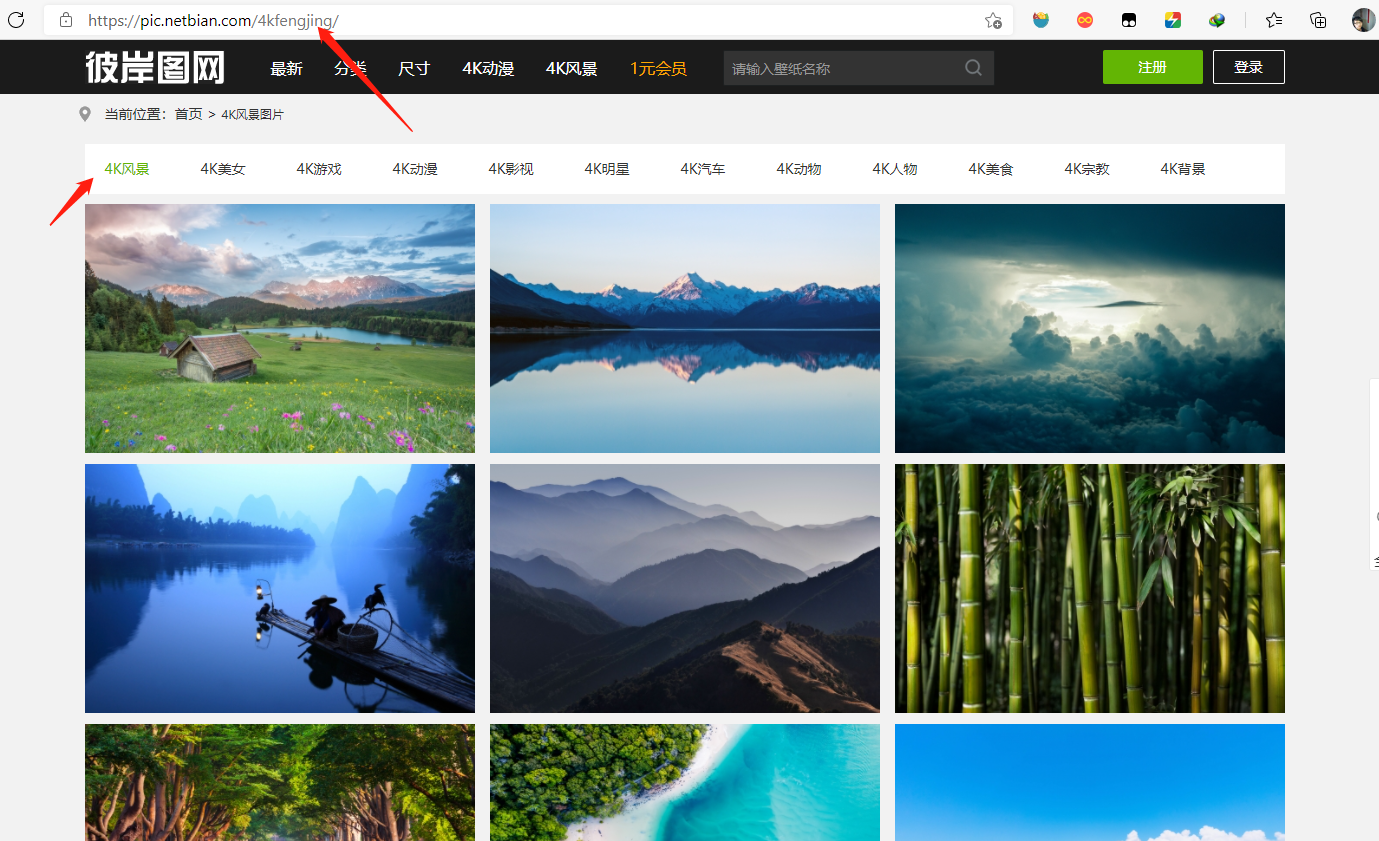
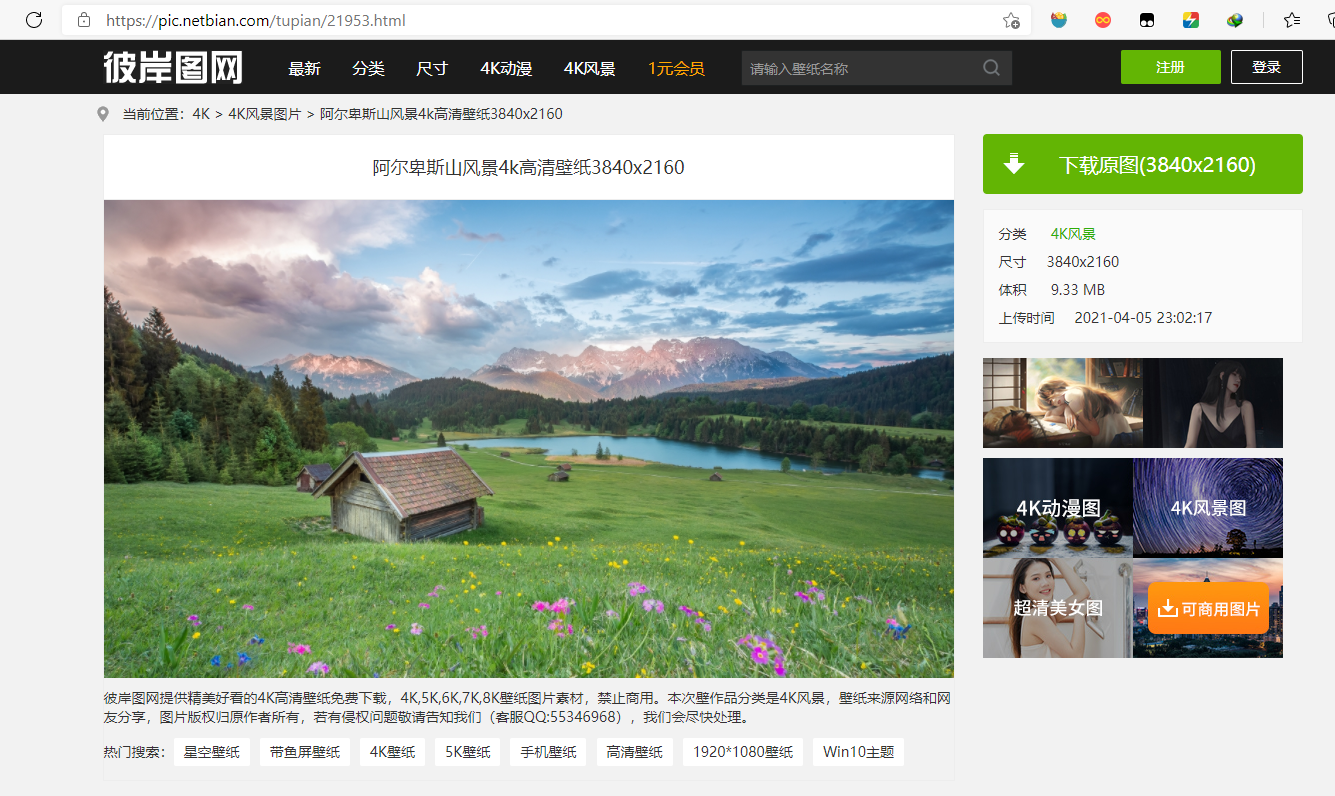
二、网络请求分析
鼠标右键点击检查,刷新页面观察浏览器请求变化,发现该页面地址栏请求为GET请求,响应数据为HTML,里面有我们需要的图片详细页面url信息,通过点击该链接,进入详细页面,详细页面可以获取到我们需要的图片url。
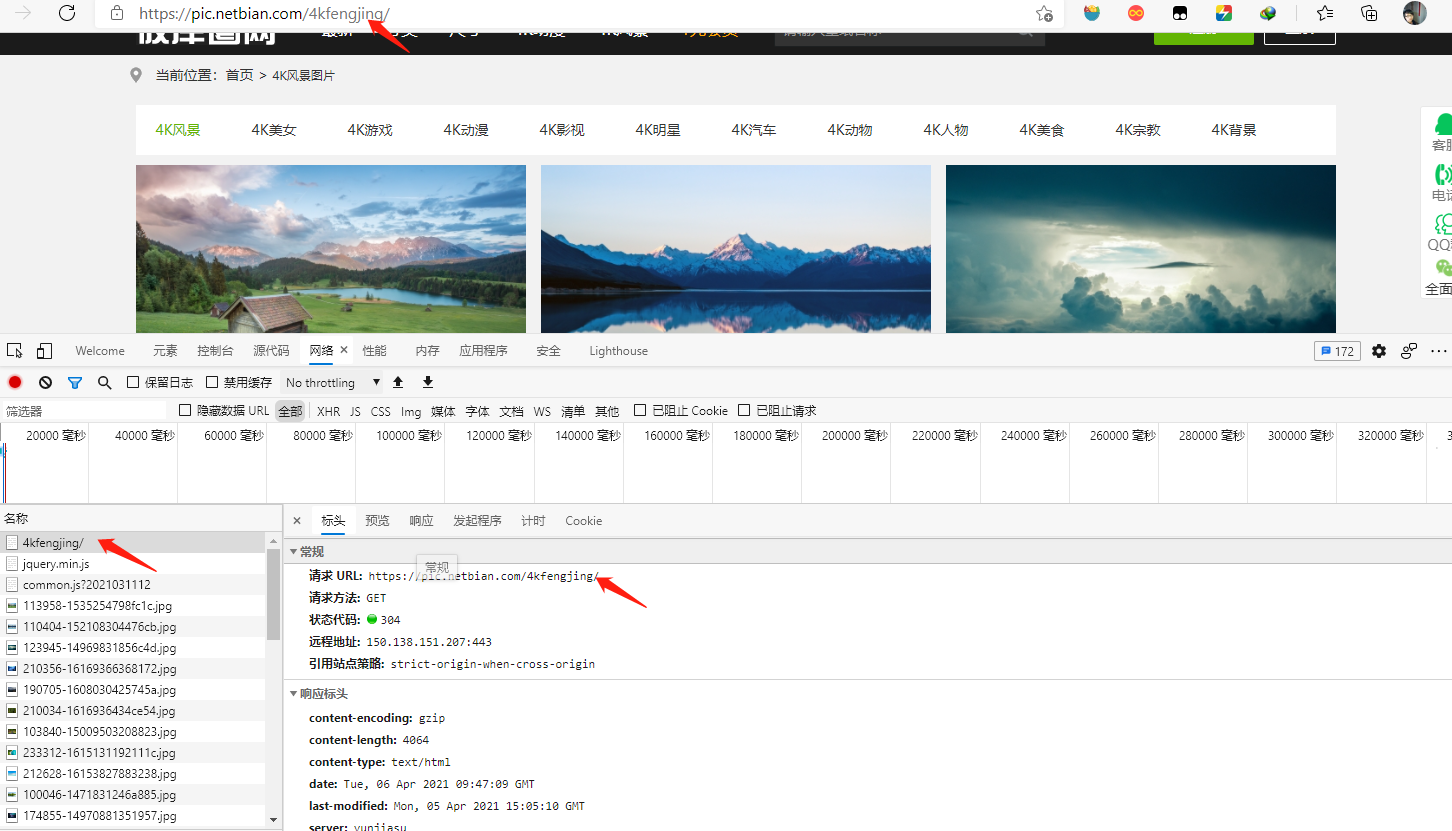
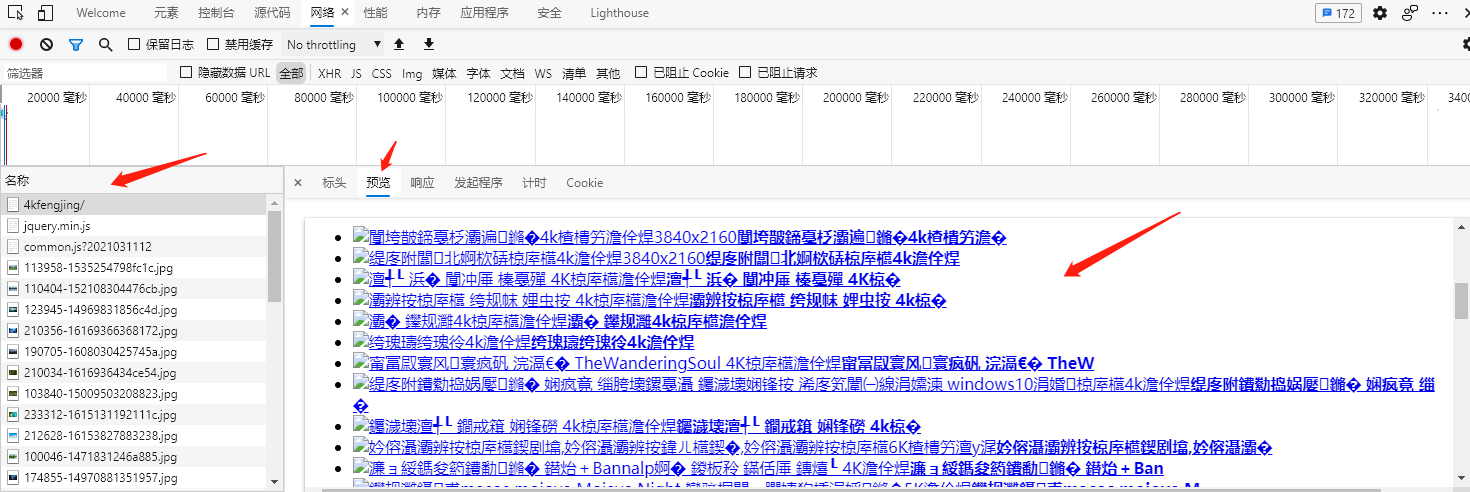
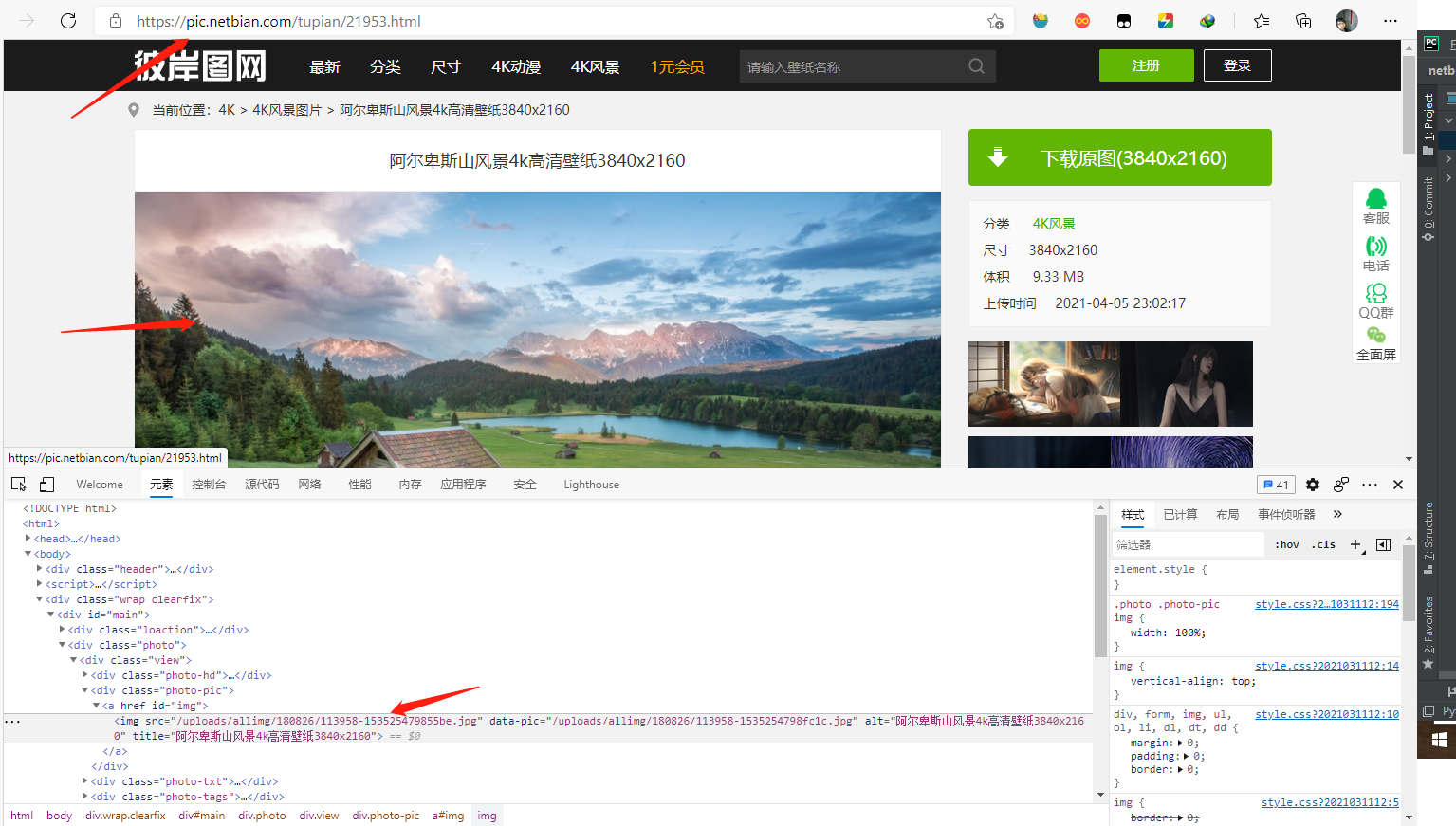
三、初步实现
代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18from urllib.parse import urljoin
from lxml import etree
import requests
url = 'https://pic.netbian.com'
response = requests.get(url)
html = etree.HTML(response.content)
for li in html.xpath('//*[@id="main"]/div[3]/ul/li'):
href = li.xpath('a/@href')[0]
uid = href.rsplit('/', maxsplit=1)[1].replace('.html', '')
title = li.xpath('a//img/@alt')[0].replace(' ', '_')
response = requests.get(urljoin(url, href))
html = etree.HTML(response.content)
img_url = urljoin(url, html.xpath('//a[@id="img"]/img/@src')[0])
print(uid, title, img_url)运行结果
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
2027188 海_少女_大鱼_女孩_唯美动漫4k壁纸3840x2160 https://pic.netbian.com/uploads/allimg/210405/224731-16176340512348.jpg
24695 下午_趴在桌子的女孩4k动漫壁纸3840x2160 https://pic.netbian.com/uploads/allimg/190824/212516-15666531161ade.jpg
27180 学生_女子_丝袜_美腿_二次元动漫美女4k壁纸 https://pic.netbian.com/uploads/allimg/210403/002739-1617380859fd5c.jpg
27074 肉骨茶_个性动漫美女_骨汤屋_二次元美女_4k动漫壁纸 https://pic.netbian.com/uploads/allimg/210318/135851-16160471316886.jpg
27160 陆萱萱_黑色丝袜美腿美女_白色衬衫_背带裤_4k美女壁纸 https://pic.netbian.com/uploads/allimg/210401/220258-16172857783909.jpg
26434 陆萱萱_白色衬衫_黑色吊带短裤_黑丝美腿美女4k壁纸 https://pic.netbian.com/uploads/allimg/201008/203736-1602160656f945.jpg
27190 LOL英雄联盟damwon_gaming_冠军皮肤_卡牌_凯南_蕾欧娜_奈德丽_烬4k壁纸 https://pic.netbian.com/uploads/allimg/210405/225104-1617634264a669.jpg
25331 女生_女子_起床_晚上_都市_夜景_4k动漫壁纸 https://pic.netbian.com/uploads/allimg/200102/193708-15779650287a6a.jpg
21953 阿尔卑斯山风景4k高清壁纸3840x2160 https://pic.netbian.com/uploads/allimg/180826/113958-153525479855be.jpg
26010 长发少女黑色吊带裙_好看的4k动漫美女壁纸3840x2160 https://pic.netbian.com/uploads/allimg/200618/005100-1592412660d6f4.jpg
17781 糖果_美女模特4k壁纸 https://pic.netbian.com/uploads/allimg/180128/112234-1517109754d925.jpg
26903 床_女孩_黑色睡衣_小乌龟_唯美插画_4k动漫壁纸 https://pic.netbian.com/uploads/allimg/210216/205419-1613480059a058.jpg
27146 古风美女_眼泪_伞_告别_唯美意境_插画_4k动漫壁纸 https://pic.netbian.com/uploads/allimg/210328/001020-1616861420d950.jpg
26780 古风_美少女_伞_长发_女孩大长腿4k唯美动漫壁纸 https://pic.netbian.com/uploads/allimg/210122/195550-1611316550d711.jpg
26123 漂亮美少女_女孩子_手机_白裤袜_美脚美腿_好看二次元4k动漫壁纸 https://pic.netbian.com/uploads/allimg/200714/224033-159473763328ff.jpg
25716 dva_宅女_长筒袜_短发_可爱女孩4k壁纸 https://pic.netbian.com/uploads/allimg/200410/213246-1586525566c099.jpg
26309 克拉女神高清女神江琴_唯美写真摄影4k电脑壁纸 https://pic.netbian.com/uploads/allimg/200910/200207-15997393279b23.jpg
24031 女孩_微笑_蹲着_水_海岸_海滩_波浪_风_夜晚_4k动漫壁纸 https://pic.netbian.com/uploads/allimg/190415/214606-15553359663cd8.jpg
25688 女孩子_旅行_车窗_火车_列车_听音乐_高清4k动漫壁纸 https://pic.netbian.com/uploads/allimg/200405/171302-15860779827765.jpg
25037 车子_少女_女生_绑辫子_唯美好看4k动漫壁纸 https://pic.netbian.com/uploads/allimg/191026/001458-157202009858e9.jpg通过以上代码,我们实现了任务的核心功能,同时验证了我们之前分析的合理性。
四、功能完善和优化
有了上一个案例的基础,我们可以仿照实现相似的功能。
版本1
代码
utils.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class Foreground:
Black = 30
Red = 31
Green = 32
Yellow = 33
Blue = 34
Purplish_red = 35
Cyan = 36
White = 37
class Background:
Black = 40
Red = 41
Green = 42
Yellow = 43
Blue = 44
Purplish_red = 45
Cyan = 46
White = 47
class Display:
Default = 0
Highlight = 1
Underline = 4
Twinkle = 5
Reverse = 7
Invisible = 8
def print_color(string: str, display_mode: int = Display.Default, foreground: int = Foreground.Green,
background: int = Background.Black):
print(f"\033[{display_mode};{foreground};{background}m{string}\033[0m")
def add_color(string: str, display_mode: int = Display.Default, foreground: int = Foreground.Green,
background: int = Background.Black):
return f"\033[{display_mode};{foreground};{background}m{string}\033[0m"spider.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165import os
from concurrent.futures.thread import ThreadPoolExecutor
from urllib.parse import urljoin
import requests
from lxml import etree
from prettytable import PrettyTable
from tqdm import tqdm
from zyf.timer import timeit
from utils import print_color
image_dir = 'images'
image_type_info = {
1: '4kfengjing', 2: '4kmeinv', 3: '4kyouxi', 4: '4kdongman',
5: '4kyingshi', 6: '4kmingxing', 7: '4kqiche', 8: '4kdongwu',
9: '4krenwu', 10: '4kmeishi', 11: '4kzongjiao', 12: '4kbeijing',
}
image_tip_info = {
1: '4K风景', 2: '4K美女', 3: '4K游戏', 4: '4K动漫',
5: '4K影视', 6: '4K明星', 7: '4K汽车', 8: '4K动物',
9: '4K人物', 10: '4K美食', 11: '4K宗教', 12: '4K背景',
}
image_data_list = set()
search_count = 0
downloaded_count = 0
success_count = 0
history_file_path = 'history.txt'
if not os.path.exists(image_dir):
os.makedirs(image_dir)
history_file = open(history_file_path, mode='a+', encoding='utf-8')
downloaded_images = set()
if os.path.exists(history_file_path):
history_file.seek(0)
downloaded_images = {line.strip() for line in history_file}
def init_tips_info():
table = PrettyTable(['序号1', '壁纸分类1', '序号2', '壁纸分类2'])
row = []
for index, key in enumerate(image_tip_info, start=1):
row.extend([key, image_tip_info[key]])
if len(row) == 4:
table.add_row(row)
row.clear()
continue
if index == len(image_type_info):
row.extend(['-', '-'])
table.add_row(row)
print(table)
def search_images(image_type: int, page_nums: int):
print(f'正在检索 - {image_tip_info[image_type]} - 请稍等 - 马上开始下载')
url = 'https://pic.netbian.com'
if image_type != 0:
url = urljoin(url, image_type_info[image_type])
image_type_desc = image_tip_info[image_type]
else:
url = url
image_type_desc = '最新壁纸'
if not os.path.exists(f'{image_dir}/{image_type_desc}'):
os.mkdir(f'{image_dir}/{image_type_desc}')
if page_nums > 1:
with ThreadPoolExecutor(max_workers=page_nums) as pool:
pool.map(get_image_data, [url for _ in range(page_nums)], [image_type_desc for _ in range(page_nums)],
range(1, page_nums + 1))
else:
get_image_data(url=url, image_type_desc=image_type_desc, page_num=page_nums)
def get_image_data(url: str, image_type_desc: str, page_num: int):
global downloaded_count, search_count
url = url if page_num == 1 else f'{url}/index_{page_num}.html'
response = requests.get(url)
html = etree.HTML(response.content)
for li in html.xpath('//*[@id="main"]/div[3]/ul/li'):
href = li.xpath('a/@href')[0]
uid = href.rsplit('/', maxsplit=1)[1].replace('.html', '')
title = li.xpath('a//img/@alt')[0].replace(' ', '_').replace(',', '-')
response = requests.get(urljoin(url, href))
html = etree.HTML(response.content)
img_url = urljoin(url, html.xpath('//a[@id="img"]/img/@src')[0])
filepath = f'{image_dir}/{image_type_desc}/{title}_{uid}.jpg'
if filepath not in downloaded_images:
search_count += 1
image_data_list.add((img_url, filepath))
else:
downloaded_count += 1
def start(image_type: int, page_nums: int):
search_images(image_type=image_type, page_nums=page_nums)
start_download(page_nums)
def start_download(workers: int):
if len(image_data_list) > 20:
data_list = [set() for _ in range(workers)]
for index, image in enumerate(image_data_list):
remainder = index % workers
data_list[remainder].add(image)
with ThreadPoolExecutor(max_workers=workers) as pool:
pool.map(download_images, data_list)
else:
download_images(image_data_list)
def download_images(data_list: set = None):
global success_count
if not data_list:
return
task_progress = tqdm(data_list, ncols=100)
for index, task in enumerate(task_progress, start=1):
url, filepath = task
task_progress.set_description(f"正在下载第 {index} 张图片")
response = requests.get(url=url)
with open(filepath, mode='wb') as f:
f.write(response.content)
history_file.write(f'{filepath}\n')
success_count += 1
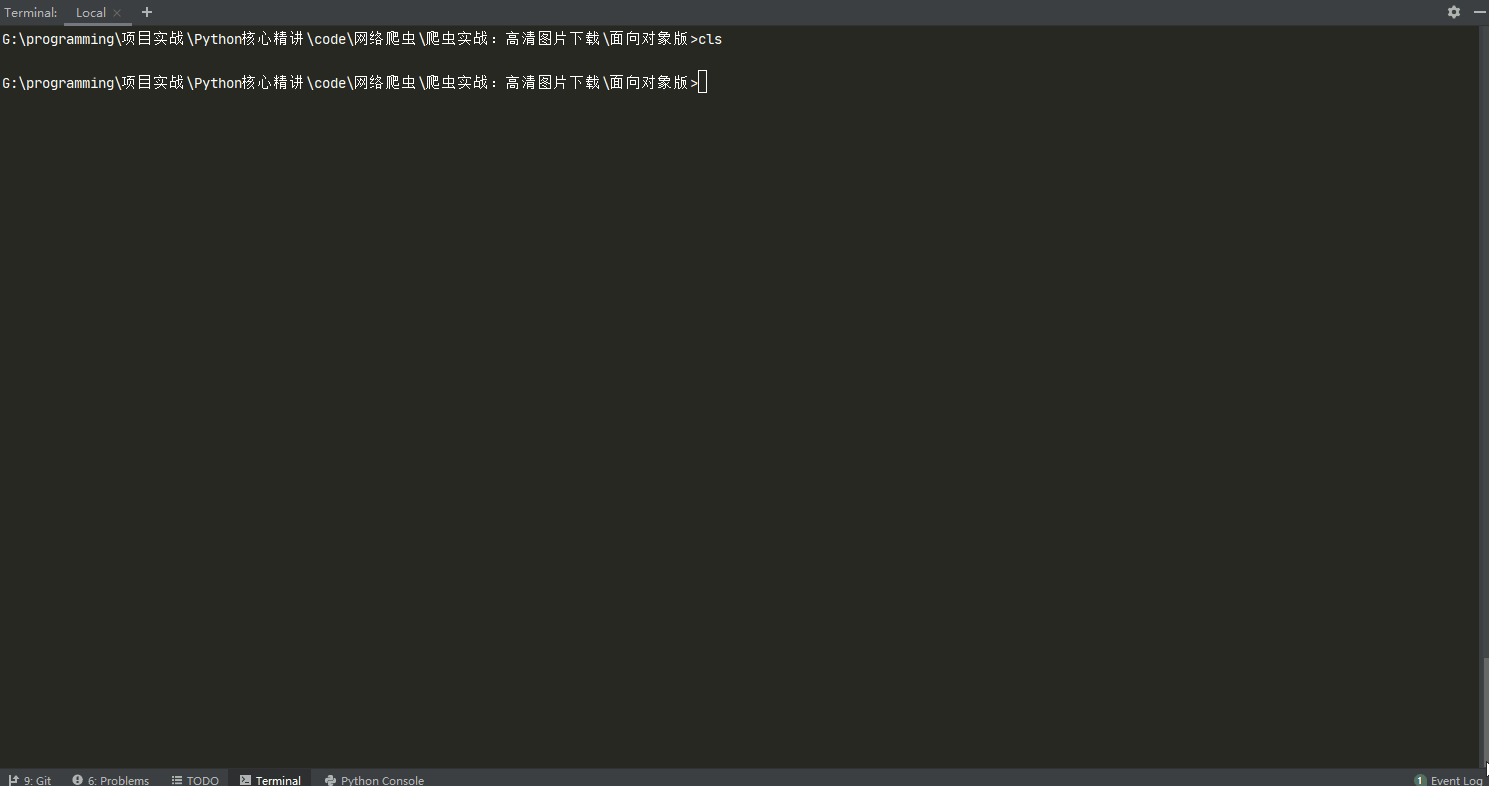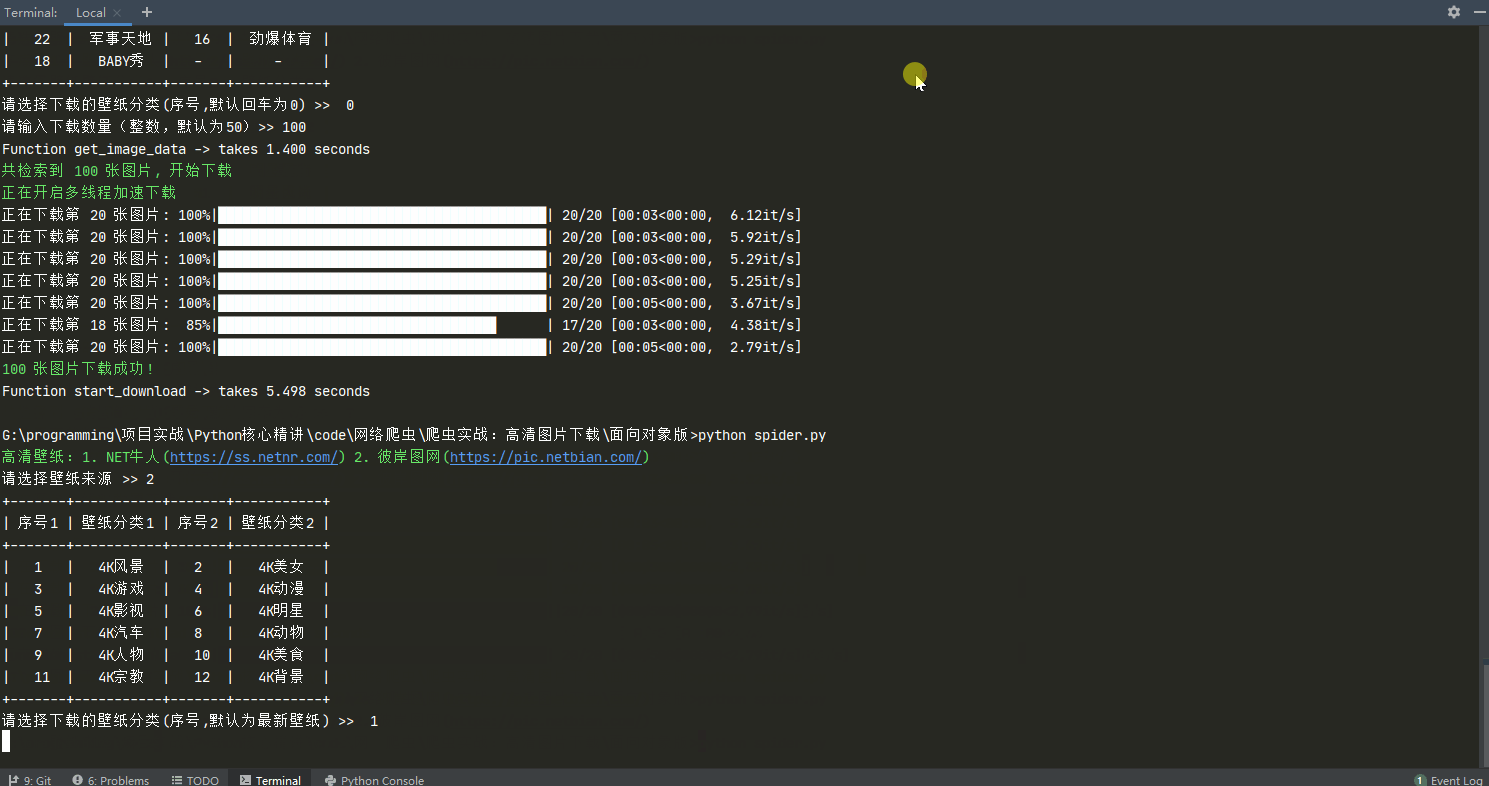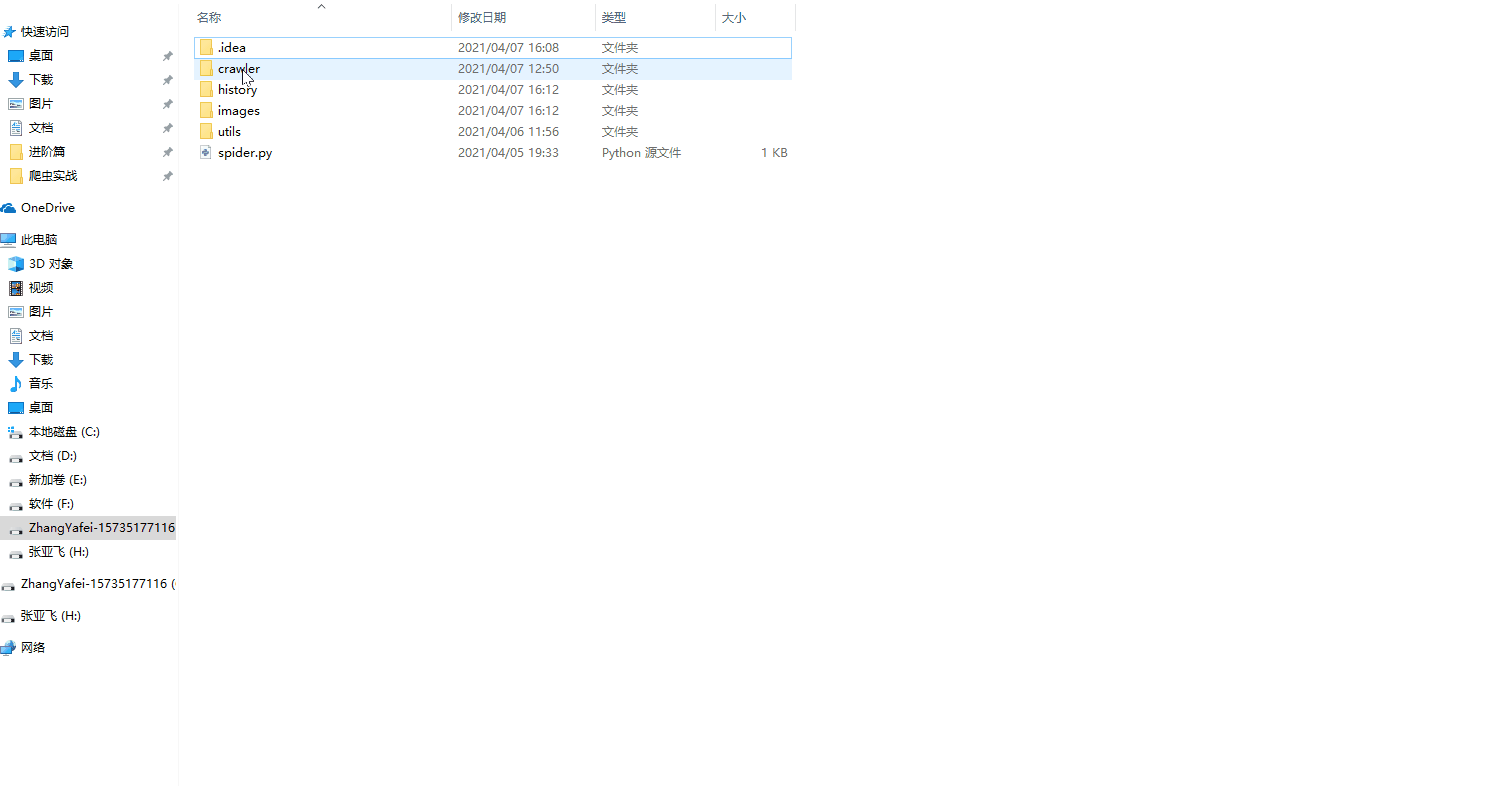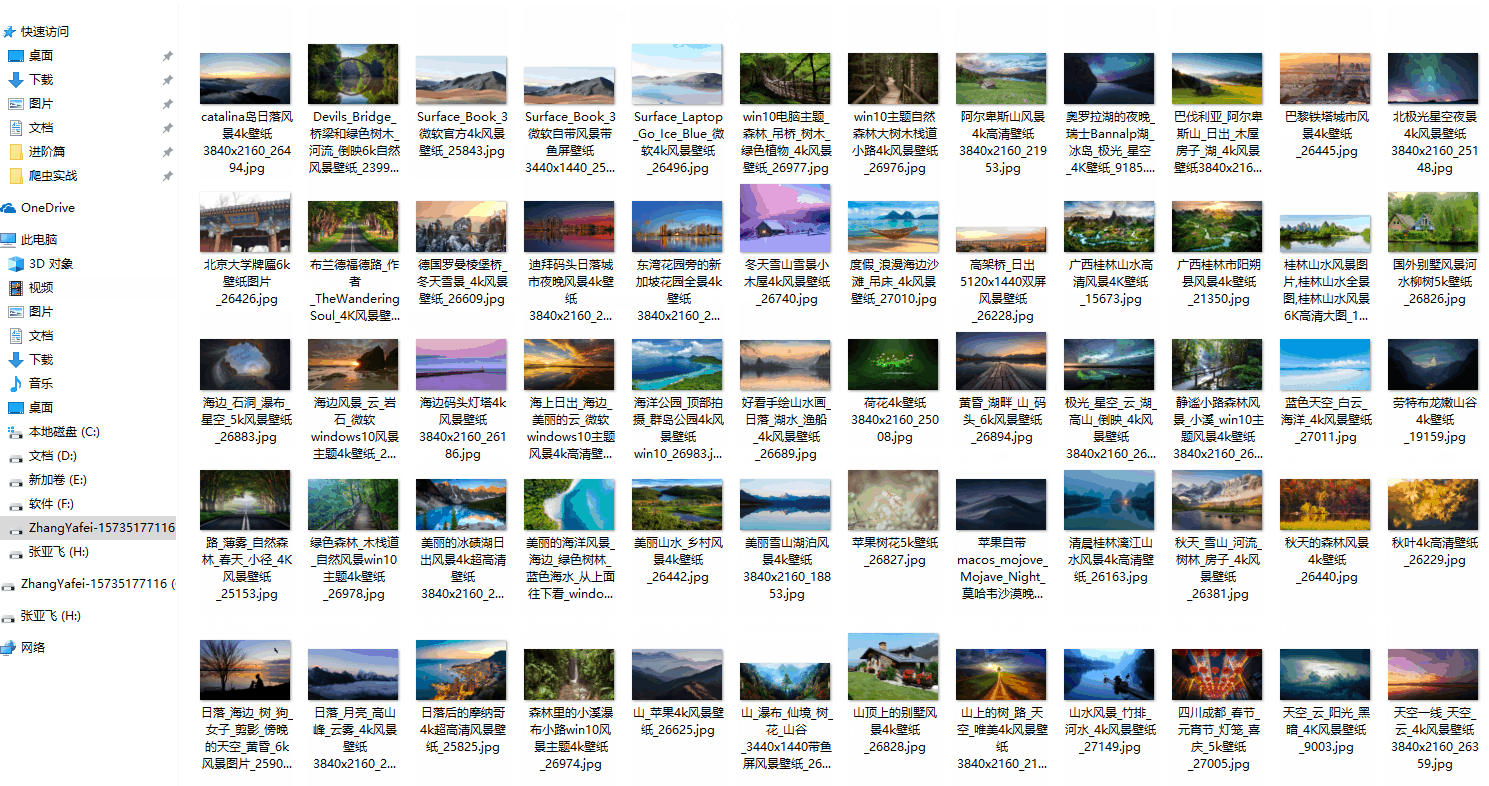
def run():
init_tips_info()
while True:
image_type = input('请选择下载的壁纸分类(序号,默认为最新壁纸) >> ')
if image_type:
if not image_type.isdecimal() or int(image_type) not in image_type_info:
print('您输入的分类序号有误,请重新确认后输入')
continue
else:
image_type = int(image_type)
else:
image_type = 0
break
while True:
page_nums = input('请输入下载页数(整数,默认为1,每页20)>> ')
if page_nums:
if not page_nums.isdecimal():
print('您输入的页数有误,必须为整数,请重新输入')
continue
else:
page_nums = int(page_nums)
else:
page_nums = 1
break
start(image_type, page_nums)
print_color(
f'\n\n共检索到 {search_count + downloaded_count} 张图片, 之前已下载 {downloaded_count} 张, 还需下载 {search_count} 张, 本次下载成功 {success_count} 张')
if __name__ == '__main__':
run()
运行结果
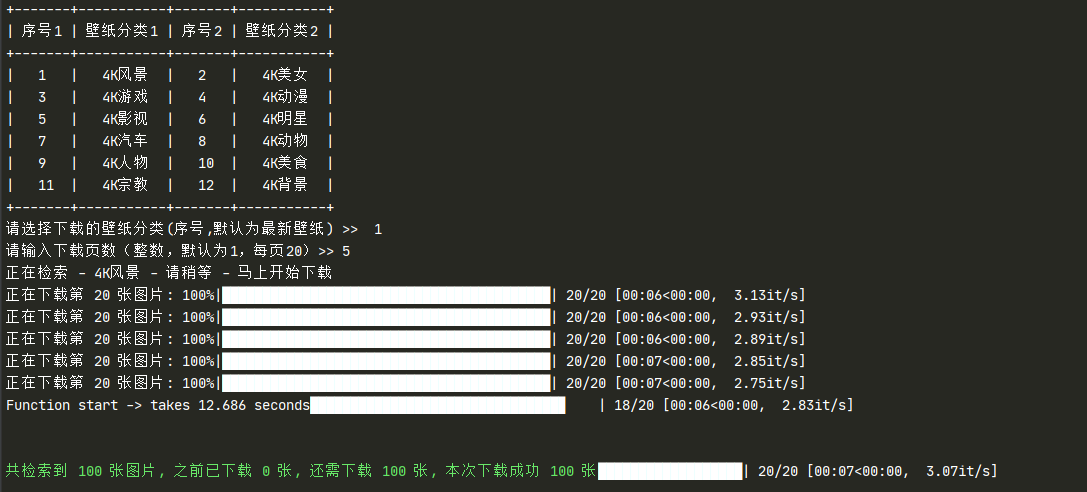
运行演示
版本2
spider.py
1 | import os |
运行结果‘

经过测试,版本1和版本2下载同样的100张图片,一个耗时12.686,一个12.961,速度几乎一致。
面向对象代码,有兴趣的伙伴可以进行学习:爬虫实战:高清图片下载
