学习目标:
掌握整型、布尔类型、字符串的必备知识。
基础数据类型:
- int,整数类型(整形)
- float,浮点类型(浮点型)
- complex,复数类型
- bool,布尔类型
- str,字符串类型
高级数据类型:
- list,列表类型
- tuple,元组类型
- dict,字典类型
- set,集合类型
之前我们简单介绍了数字(整型、浮点型、复数)、布尔型和字符串这几种基本的数据类型,接下来的三个小节将对这几种基本数据类型以及列表、元组、字典、集合等高级数据类型进行说明。
整型:Python中可以处理任意大小的整数(Python 2.x中有
int和long两种类型的整数,但这种区分对Python来说意义不大,因此在Python 3.x中整数只有int这一种了),而且支持二进制(如0b100,换算成十进制是4)、八进制(如0o100,换算成十进制是64)、十进制(100)和十六进制(0x100,换算成十进制是256)的表示法。浮点型:浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,浮点数除了数学写法(如
123.456)之外还支持科学计数法(如1.23456e2)。复数型:形如
3+5j,跟数学上的复数表示一样,唯一不同的是虚部的i换成了j。实际上,这个类型并不常用,大家了解一下就可以了。布尔型:布尔值只有
True、False两种值,要么是True,要么是False,在Python中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来(例如3 < 5会产生布尔值True,而2 == 1会产生布尔值False)。字符串型:字符串是以单引号或双引号括起来的任意文本,比如
'hello'和"hello",字符串还有原始字符串表示法、字节字符串表示法、Unicode字符串表示法,而且可以书写成多行的形式(用三个单引号或三个双引号开头,三个单引号或三个双引号结尾)。
一、 整型(int)
整型其实就是十进制整数的统称,比如:1、68、999都属于整型。一般用于表示年龄、序号等。
1. 定义
1 | number = 10 |
2. 方法
- bit_length()
- conjugate()
1 | # 独有功能1 x.bit_length() 查看该整数的二进制有多少位组成 |
3. 运算
1 | # 1. 加 |
4. 类型转换
在项目开发和试题中经常会出现一些 “字符串” 和 布尔值 转换为 整型的情况。
1 | # 布尔值转整型 |
所以,如果以后别人给你一个按 二进制、八进制、十进制、十六进制 规则存储的字符串时,可以轻松的通过int转换为十进制的整数。
二、浮点型(float)
浮点型,一般在开发中用于表示小数。
1 | v1 = 3.14 |
关于浮点型的其他知识点如下:
在类型转换时需要,在浮点型转换为整型时,会将小数部分去掉。
1
2
3v1 = 3.14
data = int(v1)
print(data) # 3想要保留小数点后N位
1
2
3v1 = 3.1415926
result = round(v1, 3)
print(result) # 3.142浮点型的坑(所有语言中)
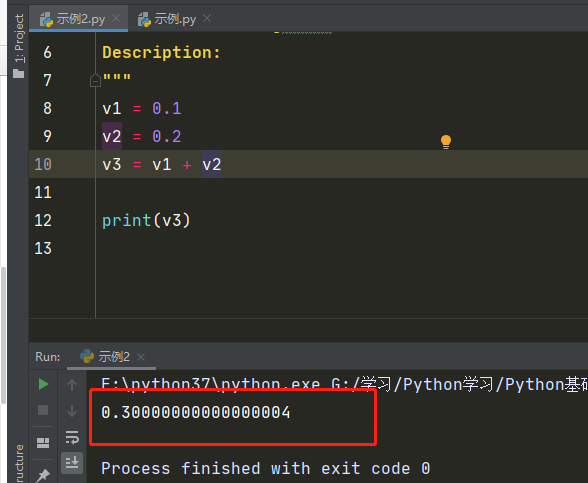
在项目中如果遇到精确的小数计算应该怎么办?
1 | import decimal |
三、布尔类型(bool)
布尔值,其实就是 “真”、“假” 。
1. 定义
1 | data = False |
2. 方法
无
3. 运算
1 | v1 = True + True |
4. 类型转换
在以后的项目开发中,会经常使用其他类型转换为布尔值的情景,此处只要记住一个规律即可。
1 | 整数0、空字符串、空列表、空元组、空字典转换为布尔值时均为False |
1 | # 练习题:查看一些变量为True还是False |
5. 应用场景
- 做条件自动转换
如果在 if 、while 条件后面写一个值当做条件时,他会默认转换为布尔类型,然后再做条件判断。
1 | if 0: # 会判断 bool(0) 为True还是False |
1 | while 1>9: # 会判断 bool(1 > 9) 为True还是False |
四、字符串类型(str)
第二次世界大战促使了现代电子计算机的诞生,最初计算机被应用于导弹弹道的计算,而在计算机诞生后的很多年时间里,计算机处理的信息基本上都是数值型的信息。世界上的第一台电子计算机叫ENIAC(电子数值积分计算机),诞生于美国的宾夕法尼亚大学,每秒钟能够完成约5000次浮点运算。随着时间的推移,虽然数值运算仍然是计算机日常工作中最为重要的事情之一,但是今天的计算机处理得更多的数据可能都是以文本的方式存在的,如果我们希望通过Python程序操作本这些文本信息,就必须要先了解字符串类型以及与它相关的知识。
所谓字符串,就是由零个或多个字符组成的有限序列。在Python程序中,如果我们把单个或多个字符用单引号或者双引号包围起来,就可以表示一个字符串。字符串中的字符可以是特殊符号、英文字母、中文字符、日文的平假名或片假名、希腊字母、Emoji字符等。我们平时会用他来表示文本信息。例如:姓名、地址、自我介绍等。
1. 定义
1 | str1 = '人生只管努力,其他交给天意' |
- 转义字符
| 转义字符 | 描述 | 实例 |
|---|---|---|
| (在行尾时) | 续行符 | >>> print("line1 \ ... line2 \ ... line3") line1 line2 line3 >>> |
| \ | 反斜杠符号 | >>> print("\\") \\ |
| ' | 单引号 | >>> print('\'') ' |
| " | 双引号 | >>> print("\"") " |
| \a | 响铃 | >>> print("\a")执行后电脑有响声。 |
| \b | 退格(Backspace) | >>> print("Hello \b World!") Hello World! |
| \000 | 空 | >>> print("\000") >>> |
| \n | 换行 | >>> print("\n") >>> |
| \v | 纵向制表符 | >>> print("Hello \v World!") Hello World! >>> |
| \t | 横向制表符 | >>> print("Hello \t World!") Hello World! >>> |
| \r | 回车 | >>> print("Hello\rWorld!") World! |
| \f | 换页 | >>> print("Hello \f World!") Hello World! >>> |
| \yyy | 八进制数,y 代表 0~7 的字符,例如:\012 代表换行。 | >>> print("\110\145\154\154\157\40\127\157\162\154\144\41") Hello World! |
| \xyy | 十六进制数,以 \x 开头,y 代表的字符,例如:\x0a 代表换行 | >>> print("\x48\x65\x6c\x6c\x6f\x20\x57\x6f\x72\x6c\x64\x21") Hello World! |
| \other | 其它的字符以普通格式输出 |
可以在字符串中使用\(反斜杠)来表示转义,也就是说\后面的字符不再是它原来的意义,例如:\n不是代表反斜杠和字符n,而是表示换行;而\t也不是代表反斜杠和字符t,而是表示制表符。所以如果想在字符串中表示'要写成\',同理想表示\要写成\\。可以运行下面的代码看看会输出什么。
1 | s1 = '\'hello, world!\'' |
在\后面还可以跟一个八进制或者十六进制数来表示字符,例如\141和\x61都代表小写字母a,前者是八进制的表示法,后者是十六进制的表示法。也可以在\后面跟Unicode字符编码来表示字符,例如\u9a86\u660a代表的是中文“骆昊”。运行下面的代码,看看输出了什么。
1 | s1 = '\141\142\143\x61\x62\x63' |
如果不希望字符串中的\表示转义,我们可以通过在字符串的最前面加上字母r来加以说明,再看看下面的代码又会输出什么。
1 | s1 = r'\'hello, world!\'' |
1 | "xxxxx".功能(...) |
2. 方法
在Python中,我们可以通过字符串类型自带的方法对字符串进行操作和处理,对于一个字符串类型的变量,我们可以用变量名.方法名()的方式来调用它的方法。所谓方法其实就是跟某个类型的变量绑定的函数,后面我们讲面向对象编程的时候还会对这一概念详加说明。
2.1 大小写相关
title(): 返回”标题化”的字符串,就是说所有单词都是以大写开始,其余字母均为小写(见istitle())upper():转换字符串中所有小写字母为大写lower:转换字符串中所有大写字符为小写capitalize():将字符串的第一个字符转换为大写swapcase:反转大小写示例
1
2
3
4
5
6
7
8
9
10# title
print('life is short, i use python'.title()) # Life Is Short, I Use Python
# 大写
print('zhangyafei'.upper()) # ZHANGYAFEI
# 小写
print('ZHANGYAFEI'.lower()) # zhangyafeI
# capitalize 首字母大写,其余字母小写
print('python'.capitalize()) # Python
# 大小写转换
print('ZhangYafei'.swapcase()) # zHANGyAFEI
2.2 查找统计操作
如果想在一个字符串中从前向后查找有没有另外一个字符串,或者统计一个字符出现的次数,可以使用字符串的find、index和count方法。
count(sub, start=None, end=None):返回 sub 在 string 里面出现的次数,start和end为起始和终止位置find(sub, start=None, end=None):检测 sub 是否包含在字符串中,如果指定范围 start 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1。rfind(sub, start=None, end=None):检测 sub 是否包含在字符串中,如果指定范围 start 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1。index(sub, start=None, end=None): 和find方法一样,只不过如果sub不在字符串中会报异常。示例
1
2
3
4
5
6
7
8
9
10
11
12print('你猜我猜不猜'.count('猜')) # 3
print('你猜我猜不猜'.find('猜')) # 1
print('你猜我猜不猜'.rfind('猜')) # 5
print('你猜我猜不猜'.index('猜')) # 1
# 在使用find和index方法时还可以通过方法的参数来指定查找的范围,也就是查找不必从索引为0的位置开始。find和index方法还有逆向查找(从后向前查找)的版本,分别是rfind和rindex,代码如下所示。
# 从前向后查找字符o出现的位置(相当于第一次出现)
print('hello good world!'.find('o')) # 4
# 从索引为5的位置开始查找字符o出现的位置
print('hello good world!'.find('o', 5)) # 7
# 从后向前查找字符o出现的位置(相当于最后一次出现)
print('hello good world!'.rfind('o')) # 12
2.3 性质判断
可以通过字符串的startswith、endswith来判断字符串是否以某个字符串开头和结尾;还可以用is开头的方法判断字符串的特征,这些方法都返回布尔值。
startswith(prefix, start=None, end=None): 检查字符串是否以 prefix开头,如果是,返回 True,否则返回 False.endswith(suffix, start=None, end=None): 检查字符串是否以 suffix结束,如果是,返回 True,否则返回 False.isalnum():如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 Falseisalpha():如果字符串至少有一个字符并且所有字符都是字母或中文字则返回 True, 否则返回 Falseisascii():检查字符串是否是所有的ascii字符编码,是返回True, 否则返回False。isdecimal():检查字符串是否只包含十进制字符,如果是返回 true,否则返回 false。isdigit():如果字符串只包含数字则返回 True 否则返回 False..isidentifier():检查字符串是否是一个有效的Python标识符,如果是返回 true,否则返回 false。islower():如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 Falseisupper():如果字符串中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 Falseisnumeric():如果字符串中只包含数字字符,则返回 True,否则返回 Falseisspace:如果字符串中只包含空白,则返回 True,否则返回 False.istitle:如果字符串是标题化的(见 title())则返回 True,否则返回 False.示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49# 判断以某字符串开头或结尾
str1 = '孟子曰:爱人者,人恒爱之;敬人者,人恒敬之。'
print(str1.startswith('孟子曰')) # True
print(str1.endswith('。')) # True
print('zyf666'.isalnum()) # True # 字符串由数字和字母组成
print('zyf'.isalpha()) # True 字符串有字母组成
print('666'.isdigit()) # True 字符串由数字组成
print('aB'.isascii()) # True
print('_123'.isidentifier()) # True
print('12_123'.isidentifier()) # False
print('abc'.islower())
print('ABC'.isupper())
print(' \n\t'.isspace())
print('Python Data Struct'.istitle())
print('Python data struct'.istitle())
# title 字符串非字母元素隔开的每个单词的首字母大写 *
# 判断字符串类型
str3 = '1' # 数字字符串
print(str3.isdigit()) # True
print(str3.isdecimal()) # True
print(str3.isnumeric()) # True
str4 = b'1' # 字节数字
print(str4.isdigit()) # True
# print(str9.isdecimal()) # 报错
# print(str9.isnumeric()) # 报错
str5 = '四' # 汉字数字
print(str5.isdigit()) # False
print(str5.isdecimal()) # False
print(str5.isnumeric()) # True
str6 = "Ⅳ" # 罗马数字
print(str6.isdigit()) # False
print(str6.isdecimal()) # False
print(str6.isnumeric()) # True
"""
isdigit()
True: Unicode数字,byte数字(单字节),全角数字(双字节)
False: 汉字数字,罗马数字,小数
Error: 无
isdecimal()
True: Unicode数字,全角数字(双字节)
False: 罗马数字,汉字数字,小数
Error: byte数字(单字节)
isnumeric()
True: Unicode数字,全角数字(双字节),罗马数字,汉字数字
False: 小数
Error: byte数字(单字节)# 格式化字符串 format
"""
2.4 格式化字符串
在Python中,字符串类型可以通过center、ljust、rjust方法做居中、左对齐和右对齐的处理,我们之前讲过,可以通过format方法对字符串进行格式化操作,还可以通过zfill进行填充0的操作。
format:字符串格式化center(width, fillchar):返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。ljust:返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。rjust:返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。zfill(width): 返回长度为 width 的字符串,原字符串右对齐,前面填充0.示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29name = "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
data = name.format("老王", "挖掘机", "修电脑")
print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等
print(name) # "{0}的喜欢干很多行业,例如有:{1}、{2} 等"
name = "{}的喜欢干很多行业,例如有:{}、{} 等"
data = name.format("老王", "挖掘机", "修电脑")
print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等
name = "{name}的喜欢干很多行业,例如有:{h1}、{h2} 等"
data = name.format(name="老王", h1="挖掘机", h2="修电脑")
print(data) # 老王的喜欢干很多行业,例如有:挖掘机、修电脑 等
v1 = "王经理"
data = v1.center(21, "-")
print(data) # ---------张经理---------
data = v1.ljust(21, "-")
print(data) # 张经理------------------
data = v1.rjust(21, "-")
print(data) # ------------------张经理
# 填充0
data = "小明"
v1 = data.zfill(10)
print(v1) # 00000000小明
# 应用场景:处理二进制数据
data = "101" # "00000101"
v1 = data.zfill(8)
print(v1) # "00000101"
2.5 修剪操作
字符串的strip方法可以帮我们获得将原字符串修剪掉左右两端空格之后的字符串。这个方法非常有实用价值,通常用来将用户输入中因为不小心键入的头尾空格去掉,strip方法还有lstrip和rstrip两个版本,相信从名字大家已经猜出来这两个方法是做什么用的。
strip:去除首尾空白字符,空白字符包含空格、\n和\tlstrip:去除字符串开头空白字符rstrip:去除字符串结尾空白字符示例
1
2
3
4
5# 去除空白 strip lstrip rstrip
str2 = " H e ll o啊,树哥 "
print(str2.strip()) # 将两边的空白去掉,得到"H e ll o啊,树哥"
print(str2.lstrip()) # 将左边的空白去掉,得到"H e ll o啊,树哥 "
print(str2.rstrip()) # 将右边的空白去掉,得到" H e ll o啊,树哥"
2.6 替换操作
replace(old, new): 把 将字符串中的 old 替换成 new,如果 max 指定,则替换不超过 max 次。示例
1
2
3
4
5# 替换 replace
video_file_name = "大话西游之月光宝盒.mp4"
new_file_name = video_file_name.replace("mp4", "avi") # "大话西游之月光宝盒.avi"
final_file_name = new_file_name.replace("月光宝盒", "仙履奇缘")
print(final_file_name)
2.7 分割操作
split(sep=' ', maxsplit=-1):以str为分隔符截取字符串,如果num有指定值,则仅截取num+1个子字符串rsplit(sep=' ', maxsplit=-1):和split,从右往左splitlines([keepends]):按照行(‘\r’, ‘\r\n’, \n’)分隔,返回一个包含各行作为元素的列表,如果参数keepends为 False,不包含换行符,如果为 True,则保留换行符。示例
1
2
3
4
5
6
7# 分割 split rsplit splitlines
str3 = "张亚飞|root|zhangyafei@qq.com"
print(str3.split('|', maxsplit=1)) # ['张亚飞', 'root|zhangyafei@qq.com']
print(str3.rsplit('|', maxsplit=1)) # ['张亚飞|root', 'zhangyafei@qq.com']
str4 = '窗前明月光\n疑是地上霜'
print(str4.splitlines()) # ['窗前明月光', '疑是地上霜']
2.8 其他操作
除了上面讲到的方法外,字符串类型还有很多方法,如拆分、合并、编码、解码等。对于字符串类型来说,还有一个常用的操作是对字符串进行匹配检查,即检查字符串是否满足某种特定的模式。例如,一个网站对用户注册信息中用户名和邮箱的检查,就属于模式匹配检查。实现模式匹配检查的工具叫做正则表达式,Python语言通过标准库中的re模块提供了对正则表达式的支持,我们会在后续的内容中为大家讲解这个知识点。
join(seq):以指定字符串作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串encode(encoding='UTF-8',errors='strict'):以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError的异常,除非 errors 指定的是’ignore’或者’replace’bytes.decode(encoding="utf-8", errors="strict"):Python3 中没有 decode 方法,但我们可以使用 bytes 对象的 decode() 方法来解码给定的 bytes 对象,这个 bytes 对象可以由 str.encode() 来编码返回。maketrans(str1, str2):创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。translate(table):根据str给出的表(包含 256 个字符)转换 string 的字符, 要过滤掉的字符放到deletechars参数中使用示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# join
print('_'.join(['Less', 'is', 'More'])) # 'Less_is_more'
# 字符串的编码和解码
data = "老大" # unicode,字符串类型
v1 = data.encode("utf-8") # utf-8,字节类型
v2 = data.encode("gbk") # gbk,字节类型
print(v1) # b'\xe8\x80\x81\xe5\xa4\xa7'
print(v2) # b'\xc0\xcf\xb4\xf3'
s1 = v1.decode("utf-8") # 老大
s2 = v2.decode("gbk") # 老大
print(s1)
print(s2)
# 映射表转换
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab) # 制作翻译表
str = "this is string example....wow!!!"
print(str.translate(trantab))
3. 运算
Python为字符串类型提供了非常丰富的运算符,我们可以使用+运算符来实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in来判断一个字符串是否包含另外一个字符串,我们也可以用[]和[:]运算符从字符串取出某个字符或某些字符。
3.1 相加:字符串 + 字符串
1 | v1 = "Michael" + "大好人" |
3.2 相乘:字符串 * 整数
1 | data = "收到" * 3 |
3.3 长度
1 | data = "人生苦短,我用Python" |
3.4 索引
如果希望从字符串中取出某个字符,我们可以对字符串进行索引运算,运算符是[n],其中n是一个整数,假设字符串的长度为N,那么n可以是从0到N-1的整数,其中0是字符串中第一个字符的索引,而N-1是字符串中最后一个字符的索引,通常称之为正向索引;在Python中,字符串的索引也可以是从-1到-N的整数,其中-1是最后一个字符的索引,而-N则是第一个字符的索引,通常称之为负向索引。注意,因为字符串是不可变类型,所以不能通过索引运算修改字符串中的字符。
1 | message = "IlovePython" |
需要提醒大家注意的是,在进行索引操作时,如果索引越界(正向索引不在0到N-1范围,负向索引不在-1到-N范围),会引发IndexError异常,错误提示信息为:string index out of range(字符串索引超出范围)。
注意:字符串中是能通过索引取值,无法修改值。【字符串在内部存储时不允许对内部元素修改,想修改只能重新创建。】
3.5 切片
如果要从字符串中取出多个字符,我们可以对字符串进行切片,运算符是[i:j:k],左闭右开,或者前取后不取,其中i是开始索引,索引对应的字符可以取到;j是结束索引,索引对应的字符不能取到;k是步长,默认值为1,表示从前向后获取相邻字符的连续切片,所以:k部分可以省略。假设字符串的长度为N,当k > 0时表示正向切片(从前向后获取字符),如果没有给出i和j的值,则i的默认值是0,j的默认值是N;当k < 0时表示负向切片(从后向前获取字符),如果没有给出i和j的值,则i的默认值是-1,j的默认值是-N - 1。如果不理解,直接看下面的例子,记住第一个字符的索引是0或-N,最后一个字符的索引是N-1或-1就行了。
1 | s = 'abc123456' |
注意:字符串中的切片只能读取数据,无法修改数据。【字符串在内部存储时不允许对内部元素修改,想要修改只能重新创建】
3.6 比较
对于两个字符串类型的变量,可以直接使用比较运算符比较两个字符串的相等性或大小。需要说明的是,因为字符串在计算机内存中也是以二进制形式存在的,那么字符串的大小比较比的是每个字符对应的编码的大小。例如A的编码是65, 而a的编码是97,所以'A' < 'a'的结果相当于就是65 < 97的结果,很显然是True;而'boy' < 'bad',因为第一个字符都是'b'比不出大小,所以实际比较的是第二个字符的大小,显然'o' < 'a'的结果是False,所以'boy' < 'bad'的结果也是False。如果不清楚两个字符对应的编码到底是多少,可以使用ord函数来获得,例如ord('A')的值是65。下面的代码为大家展示了字符串的比较运算。
1 | s1 = 'a whole new world' |
需要强调一下的是,字符串的比较运算比较的是字符串的内容,Python中还有一个is运算符(身份运算符),如果用is来比较两个字符串,它比较的是两个变量对应的字符串是否在内存中相同的位置(内存地址),简单的说就是两个变量是否对应内存中的同一个字符串。看看下面的代码就比较清楚is运算符的作用了。
1 | s1 = 'hello world' |
3.7 成员运算
Python中可以用in和not in判断一个字符串中是否存在另外一个字符或字符串,in和not in运算通常称为成员运算,会产生布尔值True或False,代码如下所示。
1 | s1 = 'hello, world' |
4. 循环遍历
while循环, 一般在做无限制(未知)循环此处时使用。
1
2
3
4
5
6message = "你打我呀" 0 1 2 3
index = 0
while index < len(message):
value = message[index]
print(value)
index += 1for循环,,一般应用在已知的循环数量的场景。
1
2
3message = "传统功夫讲四两拨千斤"
for char in message:
print(char)range,帮助我们创建一系列的数字
1
2
3
4
5
6range(10) # [0,1,2,3,4,5,6,7,8,9]
range(1,10) # [1,2,3,4,5,6,7,8,9]
range(1,10,2) # [1,3,5,7,9]
range(2, 11, 2) # [2, 4, 6, 8, 10]
range(10,1,-1) # [10,9,8,7,6,5,4,3,2]
list(range(10)) # list可以直接将range元素取出来For + range
1
2for i in range(10):
print(i)1
2
3
4message = "年轻人不讲武德"
for i in range(5): # [0,1,2,3,4]
print(message[i])1
2
3message = "传统功夫讲究接化发"
for i in range( len(message) ): # [0,1,2,3,4,5,6,7,8]
print(message[i])
5. 类型转换
其他数据类型转换为字符串的格式为:str(object)。
1 | num = 999 |
1 | data_list = ["张三","喜欢",999] |
一般情况下,只有整型转字符串才有意义。
五、 简单的总结
Python的基础数据类型就是这么多,其中知道如何表示和操作字符串对程序员来说是非常重要的,我们在处理文本信息的时候,可以用拼接、切片等运算符,也可以使用字符串类型的方法。总之,需要多练,多琢磨,多总结,才能为后续学习更复杂的数据操作打好基础。
