# 一、爬虫基本原理
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取网络信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
1. 爬虫基本流程
向服务器发起请求
获取响应内容
解析内容
保存内容
2. request和response
2.1 Request中包含哪些内容?
主要是GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等。
URL全称是统一资源定位符,如一个网页文档、一张图片、一个视频等都可以用URL来唯一来确定
包含请求时的头部信息,如User-Agent、Host、Cookies等信息
请求时额外携带的数据,如表单提交时的表单数据
2.2 Response中包含哪些内容?
有多种响应状态,如200代表成功,301代表跳转,404代表找不到页面,502代表服务器错误等
如内容类型、内容长度、服务器信息、设置cookies等等
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等。
3. 示例代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import requestsurl = "http://www.baidu.com" headers = {"User-Agent" : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.146 Safari/537.36' } response = requests.get(url=url, headers=headers) print(response.text) print(response.status_code) print(response.headers) print(response.request.headers) print(response.request.url) print(response.request.body) print(response.request.method)
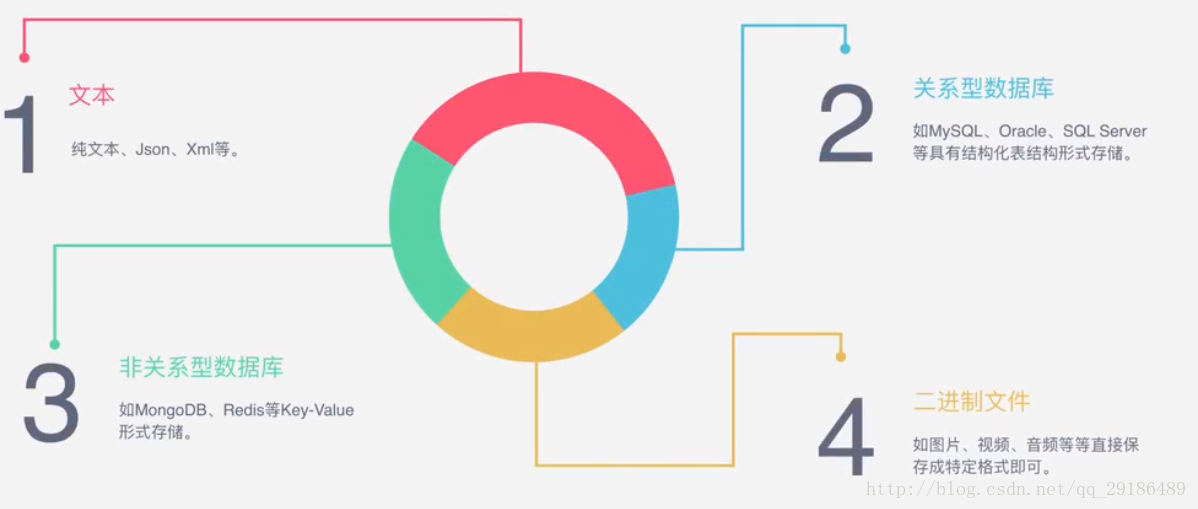
4. 能抓到怎样的数据?
网页文本:如HTML文档、JSON格式文本等
图片文件:获取的是二进制文件,保存为图片格式
视频 :同为二进制文件,保存为视频格式即可
其他 :只要能够请求到的,都能够获取到
示例:下载百度LOGO
1 2 3 4 5 6 7 import requestsresponse = requests.get("https://www.baidu.com/img/bd_logo1.png" ) with open("baidu.jpg" , "wb" ) as f: f.write(response.content)
5. 解析方式
6. 为什么我们抓到的有时候和浏览器看到的不一样? 有时候,网页返回是JS动态加载的,直接用请求库访问获取到的是JS代码,不是渲染后的结果。
怎样保存数据?
好了,有了这些基础知识以后,就开始咱们的学习之旅吧!
拓展-web请求相关:https://www.cnblogs.com/zhangyafei/p/10225977.html
二、环境配置
下载数据 - urllib / requests / aiohttp。
解析数据 - re / lxml / beautifulsoup4(bs4)/ pyquery。
缓存和持久化 - pymysql / sqlalchemy / peewee/ redis / pymongo。
生成数字签名 - hashlib。
序列化和压缩 - pickle / json / zlib。
调度器 - 进程(multiprocessing) / 线程(threading) / 协程(coroutine)。
爬虫框架:scrapy。
自动化测试工具:selenium。
三、请求库:reqeusts 还得我们第一个案例吗?就是用的requests请求库请求的百度首页。
1. 请求
requests.post('http://www.httpbin.org/post')requests.put('http://www.httpbin.org/put')requests.delete('http://www.httpbin.org/delete')requests.head('http://www.httpbin.org/get')requests.options('http://www.httpbin.org/get')
1.1 基本get请求 1 2 3 4 import requestsresponse = requests.get('http://www.httpbin.org/get' ) print(response.text)
输出
1 2 3 4 5 6 7 8 9 10 11 { "args" : {}, "headers" : { "Accept" : "*/*" , "Host" : "www.httpbin.org" , "User-Agent" : "python-requests/2.24.0" , "X-Amzn-Trace-Id" : "Root=1-6029302d-3a732a0477bcaad07880e6d2" }, "origin" : "183.202.194.230" , "url" : "http://www.httpbin.org/get" }
1.2 带参数的get请求 1 2 3 4 5 6 7 import requestsdata ={ 'name' :'germey' , 'age' :22 } response = requests.get('http://www.httpbin.org/get' ,params=data) print(response.text)
输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { "args" : { "age" : "22" , "name" : "zhangyafei" }, "headers" : { "Accept" : "*/*" , "Host" : "www.httpbin.org" , "User-Agent" : "python-requests/2.24.0" , "X-Amzn-Trace-Id" : "Root=1-602930ca-1a38ccfc10f538ee68116bb4" }, "origin" : "183.202.194.230" , "url" : "http://www.httpbin.org/get?name=zhangyafei&age=22" }
1.3 解析json 1 2 3 4 5 6 import requests,jsonresponse = requests.get('http://www.httpbin.org/get' ) print(type(response.text)) print(response.text) print(response.json()) print(json.loads(response.text))
1 2 3 4 5 6 import requestsheaders = { "User-Agent" :"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0" } response = requests.get('https://www.zhihu.com/explore' ,headers=headers) print(response.text)
1.5 获取二进制数据 1 2 3 4 5 6 7 8 import requestsresponse = requests.get('https://github.com/favicon.ico' ) print(type(response.text),type(response.content)) print(response.content) print(response.text) with open('logo.gif' ,'wb' ) as f: f.write(response.content)
1.6 post请求 1 2 3 4 5 import requestsdata = {'name' :'kobe' ,'age' :'23' } response = requests.post('http://www.httpbin.org/post' ,data=data) print(response.text) print(response.json())
2. 响应 1 2 3 4 5 6 7 8 9 import requestsresponse= requests.get('http://www.jianshu.com' ) response.encoding = response.apparent_encoding print(type(response.status_code),response.status_code) print(type(response.headers),response.headers) print(type(response.cookies),response.cookies) print(type(response.url),response.url) print(type(response.history),response.history)
状态码判断
1 2 3 4 5 6 7 import requestsresponse = requests.get('http://www.jianshu.com' ) exit()if not response.status_code == requests.codes.ok else print('requests succfully' ) import requestsresponse = requests.get('http://www.jianshu.com' ) exit() if not response.status_code == 200 else print('requests succfully' )
3. 文件上传 1 2 3 4 import requestsfiles = {'file' : open('images/logo.gif' ,'rb' )} response = requests.post('http://www.httpbin.org/post' , files=files) print(response.text)
4. cookie 1 2 3 4 5 import requestsresponse = requests.get('http://www.baidu.com' ) print(response.cookies) for key,value in response.cookies.items(): print(key+'=' +value)
5. 会话维持 普通reqeusts请求
1 2 3 4 5 6 7 8 9 import requestsrequests.get('http://www.httpbin.org/cookies/set/number/123456789' ) response = requests.get('http://www.httpbin.org/cookies' ) print(response.text) ''' { "cookies": {} } '''
session方式
1 2 3 4 5 6 7 8 9 10 11 12 import requestss = requests.Session() s.get('http://www.httpbin.org/cookies/set/number/123456789' ) response = s.get('http://www.httpbin.org/cookies' ) print(response.text) ''' { "cookies": { "number": "123456789" } } '''
6. 代理设置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsheaders = { 'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36' } proxies = { 'http' : '183.166.97.210:9999' , 'https' : '171.13.4.31:9999' , } response = requests.get('http://icanhazip.com' ,headers=headers) print(response.text) response = requests.get('http://icanhazip.com' ,headers=headers, proxies=proxies) print(response.text)
7. 超时设置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsresponse = requests.get('https://www.taobao.com' ,timeout=1 ) print(response.status_code) import requestsfrom requests.exceptions import ReadTimeouttry : response = requests.get('http://www.httpbin.org' ,timeout=0.1 ) print(response.status_code) except : print('TIME OUT' )
8. 异常处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import requestsfrom requests.exceptions import Timeoutfrom requests.auth import HTTPBasicAuthtry : response = requests.get('http://120.27.34.24:9001' ,auth=HTTPBasicAuth('user' ,'123' )) print(response.status_code) except Timeout:print('time out' ) import requestsresponse = requests.get('http://120.27.34.24:9001' ,auth=('user' ,'123' )) print(response.status_code) import requestsfrom requests.exceptions import ReadTimeout,HTTPError,ConnectionError,RequestExceptiontry : response = requests.get('http://www.httpbin.org/get' ,timeout=0.5 ) print(response.status_code) except ReadTimeout: print('TIME OUT' ) except ConnectionError: print('Connect error' ) except RequestException: print('request exception' ')
四、数据解析 1. 正则匹配 正则表达式与re模块介绍:https://www.cnblogs.com/zhangyafei/articles/10113408.html
正则表达式应用:https://www.cnblogs.com/zhangyafei/p/10929290.html
1.1 糗事百科图片解析下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import osimport reimport requestsdef main () : url = "https://www.qiushibaike.com/imgrank/page/{}/" ua_headers = {"User-Agent" : 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)' } page_start = int(input('请输入开始页面:' )) page_end = int(input('请输入结束页面:' )) if not os.path.exists('Images' ): os.mkdir('Images' ) for page in range(page_start, page_end + 1 ): print('正在下载第%d页图片...' % page) new_url = url.format(page) print(new_url) responses = requests.get(url=new_url, headers=ua_headers) if responses.status_code == 200 : res = responses.text else : print('页面没有响应' ) continue pattern = re.compile('''<div class="thumb">.*?<img src="(.*?)".*?>.*?</div>''' , re.S) items = re.findall(pattern, res) for item in items: url_image = 'https:' + item name_image = item.split('/' )[-1 ] image_path = 'Images/' + name_image image_data = requests.get(url=url_image, headers=ua_headers).content with open(image_path, 'wb' ) as f: f.write(image_data) if __name__ == '__main__' : main()
运行
1 2 3 4 5 6 7 8 请输入开始页面:1 请输入结束页面:3 正在下载第1 页图片... https:// www.qiushibaike.com/imgrank/ page/1/ 正在下载第2 页图片... https:// www.qiushibaike.com/imgrank/ page/2/ 正在下载第3 页图片... https:// www.qiushibaike.com/imgrank/ page/3/
2. BeautifulSoup
2.1 基本使用 1 2 3 4 5 6 7 from bs4 import BeautifulSoupimport requestsr = requests.get('https://m.weibo.cn' ) soup = BeautifulSoup(r.text,'lxml' ) print(soup.prettify()) print(soup.title.string)
2.2 选择器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from bs4 import BeautifulSoupimport requestsr = requests.get('https://m.weibo.cn' ) soup = BeautifulSoup(r.text,'lxml' ) print(soup.title) print(type(soup.title)) print(soup.head) print(soup.p) print(soup.title.name) print(soup.p.attrs['class' ]) print(soup.p['class' ]) print(soup.title.string) print(soup.head.title.string) print(soup.div.contents) print(soup.div.children) for i,child in enumerate(soup.div.children):print(i,child) print(soup.div.descendants) for i,child in enumerate(soup.div.descendants): print(i,child) print(soup.p.parent) print(list(enumerate(soup.p.parents))) print(list(enumerate(soup.p.next_siblings))) print(list(enumerate(soup.p.previous_siblings)))
标准选择器
find_all(name,attrs,recursive,text,**kwargs)
可根据标签名,属性,内容查找文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from bs4 import BeautifulSoupimport requestsr = requests.get('https://m.weibo.cn' ) soup = BeautifulSoup(r.text,'lxml' ) print(soup.find_all('p' )) print(type(soup.find_all('p' )[0 ])) for div in soup.find_all('div' ):print(div.find_all('p' )) print(soup.find_all(attrs={'id' :'app' })) print(soup.find_all(id='app' )) print(soup.find_all(class_='wb-item' )) print(soup.find_all(text='赞' ))
find(name,attrs,recursive,text,**kwagrs)
1 2 3 4 5 6 7 from bs4 import BeautifulSoupimport requestsr = requests.get('https://m.weibo.cn' ) soup = BeautifulSoup(r.text,'lxml' ) print(soup.find('p' )) print(type(soup.find('p' )))
除此之外还有:
find_parents() 和find_parent()
find_next_siblings()和find_next_silbing()
find_previous_siblings()和find_previous_sibling()
find_all_next()和find_next()
find_all_previous()和find_previous()
css选择器
通过select()直接传给选择器即可完成传值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from bs4 import BeautifulSoupimport requestsr = requests.get('https://m.weibo.cn' ) soup = BeautifulSoup(r.text,'lxml' ) print(soup.select('#app' )) print(soup.select('p' )) print(soup.select('.surl-text' )) divs = soup.select('div' ) for div in divs: print(div.select('p' )) for div in soup.select('div' ): print(div['class' ]) print(div.attrs['class' ]) for div in soup.select('div' ): print(div.get_text())
2.3 使用总结
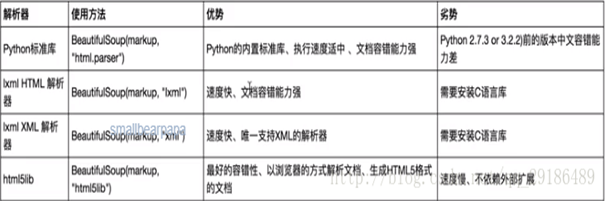
1.推荐使用lxml解析器,必要时选择html.parser
2.标签选择功能弱但是速度快
3.建议使用find和find_all查询选择单个或多个结果
4.如果对css选择器熟悉使用select()
5.记住常用的获取属性和文本值的方法
3. pyquery 强大又灵活的网页解析库,如果你嫌正则太麻烦,beautifulsoup语法太难记,又熟悉jQuery,pyquery是最好的选择
3.1 初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) print(doc('a' )) from pyquery import PyQuery as pqdoc = pq(url='https://www.baidu.com' ) print(doc('head' )) from pyquery import PyQuery as pqdoc = pq(filename='weibo.html' ) print(doc('li' ))
3.2 css选择器 1 2 3 4 5 6 from pyquery import PyQuery as pqheaders = { 'User-Agent' : 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.139 Mobile Safari/537.36' } doc = pq(url='https://www.baidu.com' ,headers=headers) print(doc('a' ))
3.3 查询元素
子元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) items = doc('.nav-bd' ) print(items) li = items.find('li' ) print(type(li)) print(li) lis = items.children() print(type(lis)) print(lis) lis = items.children('.active' ) print(type(lis)) print(lis)
父元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.baidu.com' ) doc = pq(html.text) print(doc) items = doc('.pipe' ) parent = items.parent() print(type(parent)) print(parent) from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) items = doc('.pipe' ) parents = items.parents() print(type(parents)) print(parents)
兄弟元素
1 2 3 4 5 6 7 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) li = doc('.nav-bd .pipe' ) print(li.siblings()) print(li.siblings('.active' ))
3.4 遍历 1 2 3 4 5 6 7 8 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) lis = doc('.pipe' ).items() print(lis) for li in lis: print(li)
3.5 获取信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) a = doc('a' ) print(a) for a1 in a.items(): print(a1.attr('href' )) print(a1.attr.href) from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) items = doc('.nav-bd' ) print(items.text()) from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) items = doc('.nav-bd' ) print(items) print(items.html())
3.6 dom操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) li = doc('.nav-bd .active' ) li.removeClass('.active' ) print(li) li.addClass('.active' ) print(li) from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) lis = doc('.nav-bd li' ) lis.attr('name' ,'link' ) print(lis) lis.css('font' ,'14px' ) print(lis) from pyquery import PyQuery as pqimport requestshtml = requests.get('https://www.taobao.com' ) doc = pq(html.text) items = doc('.nav-bd a' ) print(items.text()) items.find('p' ).remove() print(items.text())
其他dom方法http://pyquery.readthedocs.io/en/latest/api.html http://jquery.cuishifeng.cn
4. xpath和css解析 lxml是python解析速度最快的库之一,scrapy框架解析方法底层也是基于lxml,具体使用包含xpath和css两大类。
具体语法参考:https://www.cnblogs.com/zhangyafei/p/9947756.html
5. 四大解析器性能对比 https://www.cnblogs.com/zhangyafei/p/10521310.html
五、selenium 自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题
1. 基本使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.wait import WebDriverWaitbrowser = webdriver.Chrome() try : browser.get('https://www.baidu.com' ) input = browser.find_element_by_id('kw' ) input.send_keys('Python' ) input.send_keys(Keys.ENTER) wait = WebDriverWait(browser,10 ) wait.until(EC.presence_of_element_located((By.ID,'content_left' ))) print(browser.current_url) print(browser.get_cookies) print(browser.page_source) finally :browser.close()
2. 声明浏览器对象 1 2 3 4 5 6 from selenium import webdriverbrowser = webdriver.Chrome() browser = webdriver.Firefox() browser = webdriver.PhantomJS() browser = webdriver.Edge() browser = webdriver.Safari()
3. 访问页面 1 2 3 4 5 from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.taobao.com' ) print(browser.page_source) browser.close()
4. 查找元素 常用基本方法
find_elements_by_id
find_elements_by_name
find_elements_by_xpath
find_elements_by_css_selector
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.taobao.com' ) input_first = browser.find_element_by_id('q' ) input_second = browser.find_element_by_css_selector('#q' ) input_third = browser.find_element_by_xpath('//*[@id="q"]' ) print(input_first,input_second,input_third) browser.close() find_element_by_id find_element_by_name find_element_by_xpath find_element_by_css_selector find_element_by_link_text find_element_by_partial_link_text find_element_by_tag_name find_element_by_class_name from selenium import webdriverfrom selenium.webdriver.common.by import Bybrowser = webdriver.Chrome() browser.get('https://www.baidu.com' ) input_first = browser.find_element(By.ID,'kw' ) print(input_first) browser.close() from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.taobao.com' ) lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li' ) print(lis) browser.close() from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.taobao.com' ) lis = browser.find_elements_by_css_selector('.service-bd li' ) print(lis) browser.close()
5. 元素交互 对元素进行获取的操作,交互操作,将动作附加到动作链中串行执行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from selenium import webdriverfrom selenium.webdriver import ActionChainsbrowser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to_frame('iframeResult' ) source = browser.find_element_by_css_selector('#draggable' ) target = browser.find_element_by_css_selector('#droppable' ) actions = ActionChains(browser) actions.drag_and_drop(source,target) actions.perform() from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore' ) browser.execute_script('window.scrollTo(0,document.body.scrollHeight)' ) browser.execute_script('alert("to button")' ) from selenium import webdriverfrom selenium.webdriver import ActionChainsbrowser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) logo = browser.find_element_by_id('zh-top-link-logo' ) print(logo) print(logo.get_attribute('class' )) from selenium import webdriverfrom selenium.webdriver import ActionChainsbrowser = webdriver.Chrome() url = "https://www.zhihu.com/explore" browser.get(url) input = browser.find_element_by_class_name('zu-top-add-question' ) print(input.text) print(input.id) print(input.location) print(input.tag_name) print(input.size) from selenium import webdriverfrom selenium.webdriver import ActionChainsbrowser = webdriver.Chrome() url = 'http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable' browser.get(url) browser.switch_to.frame('iframeResult' ) source = browser.find_element_by_css_selector('#draggable' ) print(source) try : logo = browser.find_element_by_class_name('logo' ) except Exception as e: print(e) browser.switch_to.parent_frame() logo = browser.find_element_by_class_name('logo' ) print(logo) print(logo.text)
6. 等待 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from selenium import webdriverbrowser = webdriver.Chrome() browser.implicitly_wait(10 ) browser.get('https://www.zhihu.com/explore' ) input = browser.find_element_by_class_name('zu-top-add-question' ) print(input) browser.close() from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECbrowser = webdriver.Chrome() browser.get('https://www.taobao.com/' ) wait = WebDriverWait(browser,10 ) input = wait.until(EC.presence_of_element_located((By.ID,'q' ))) button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search' ))) print(input,button) browser.close()
7. 前进后退 1 2 3 4 5 6 7 8 9 10 import timefrom selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.baidu.com/' ) browser.get('https://www.taobao.com/' ) browser.get('https://www.python.org/' ) browser.back() time.sleep(1 ) browser.forward() browser.close()
8. 选项卡管理 1 2 3 4 5 6 7 8 9 10 11 12 13 from selenium import webdriverimport timebrowser = webdriver.Chrome() browser.get('https://www.baidu.com' ) browser.execute_script('window.open()' ) print(browser.window_handles) browser.switch_to_window(browser.window_handles[1 ]) browser.get('https://www.taobao.com' ) time.sleep(1 ) browser.switch_to_window(browser.window_handles[0 ]) browser.get('https://www.python.org' ) print(browser.page_source)
9. cookie 1 2 3 4 5 6 7 8 9 from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore' ) print(browser.get_cookies()) browser.add_cookie({'name' :'name' ,'domian' :'www.zhihu.com' ,'value' :'kobe' }) print(browser.get_cookies()) browser.delete_all_cookies() print(browser.get_cookies()) browser.close()
10. 异常处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 from selenium import webdriverfrom selenium.common.exceptions import TimeoutException,NoSuchElementExceptionbrowser = webdriver.Chrome() try : browser.get('https://www.baidu.com' ) except TimeoutException: print('TIME OUT' ) try : browser.find_element_by_id('hello' ) except NoSuchElementException: print('No Element' ) finally : browser.close()
11. 综合示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 """ Created on Tue Jul 31 16:41:13 2018 @author: Zhang Yafei """ from selenium import webdriverimport timeimport selenium.webdriver.support.ui as uifrom selenium.webdriver import ActionChainsfrom selenium.common.exceptions import UnexpectedAlertPresentExceptionbrowser = webdriver.Chrome() browser.get('https://www.taobao.com' ) browser.find_element_by_id('q' ).send_keys('爬虫' ) browser.find_element_by_xpath('//*[@id="J_TSearchForm"]/div[1]/button' ).click() browser.execute_script('window.open()' ) browser.switch_to_window(browser.window_handles[1 ]) browser.get('https://www.baidu.com' ) print(browser.window_handles) time.sleep(1 ) browser.switch_to_window(browser.window_handles[0 ]) browser.get('http://china.nba.com/' ) browser.switch_to_window(browser.window_handles[1 ]) browser.find_element_by_name('wd' ).send_keys('张亚飞' ) browser.find_element_by_class_name('s_ipt' ).click() wait = ui.WebDriverWait(browser,10 ) wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[@class="n"]' )) for i in range(1 ,10 ): wait = ui.WebDriverWait(browser,10 ) wait.until(lambda browser: browser.find_element_by_xpath('//div[@id="page"]/a[3]' )) browser.find_element_by_xpath('//div[@id="page"]/a[{}]' .format(i)).click() time.sleep(2 ) browser.close() browser.switch_to_window(browser.window_handles[0 ]) browser.close() from selenium import webdriverbrowser = webdriver.Chrome() browser.get('https://www.zhihu.com/explore' ) browser.execute_script('window.scrollTo(0,document.body.scrollHeight)' ) browser.execute_script('alert("to button")' )
12. 案例:爬取淘宝商品 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 """ Created on Tue Jul 31 20:59:41 2018 @author: Zhang Yafei """ from selenium import webdriverimport timeimport reimport urllib.requestimport os import tracebackdef spider (id) : rootdir = os.path.dirname(__file__)+'/images' browser = webdriver.Chrome() browser.get('https://detail.tmall.com/item.htm?id={}' .format(id)) time.sleep(20 ) b = browser.find_elements_by_css_selector('#J_DetailMeta > div.tm-clear > div.tb-property > div > div.tb-key > div > div > dl.tb-prop.tm-sale-prop.tm-clear.tm-img-prop > dd > ul > li > a' ) i=1 for a in b: style = a.get_attribute('style' ) try : image = re.match('.*url\((.*?)\).*' ,style).group(1 ) image_url = 'http:' +image image_url = image_url.replace('"' ,'' ) except : pass name = a.text print('正在下载{}' .format(a.text)) try : name = name.replace('/' ,'' ) except : pass try : urllib.request.urlretrieve(image_url,rootdir+'/{}.jpg' .format(name)) print('{}下载成功' .format(a.text)) except Exception as e: print('{}下载失败' .format(a.text)) print(traceback.format_exc()) pass finally : i+=1 print('下载完成' ) def main () : ids = ['570725693770' ,'571612825133' ,'565209041287' ] for id in ids: spider(id) if __name__ == '__main__' : main()
13. 其他 selenium常用操作:https://www.cnblogs.com/zhangyafei/p/10582977.html
selenium实现并发:https://www.cnblogs.com/zhangyafei/p/11075243.html
六、Scrapy 解读Scrapy框架:https://www.cnblogs.com/zhangyafei/p/10226853.html
Scrapy命令行工具:https://www.cnblogs.com/zhangyafei/p/10851826.html
Scrapy的Item_loader机制详解:https://www.cnblogs.com/zhangyafei/p/11956000.html
七、并发和异步爬虫 爬虫高性能相关:https://www.cnblogs.com/zhangyafei/p/10244633.html
asyncio异步编程
爬虫其他知识:https://www.cnblogs.com/zhangyafei/articles/10116542.html