学习目标:
掌握函数的基本知识点
本节导语:函数应该做一件事。做好这件事。只能做这一件事
一、何为函数
在讲解本节课的内容之前,我们先来研究一道数学题,请说出下面的方程有多少组正整数解。
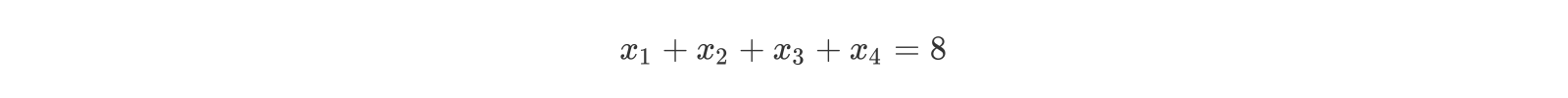
你可能已经想到了,这个问题其实等同于将8个苹果分成四组且每组至少一个苹果有多少种方案,因此该问题还可以进一步等价于在分隔8个苹果的7个空隙之间插入三个隔板将苹果分成四组有多少种方案,也就是从7个空隙选出3个空隙放入隔板的组合数,所以答案是C(7,3)=35。组合数的计算公式如下所示。
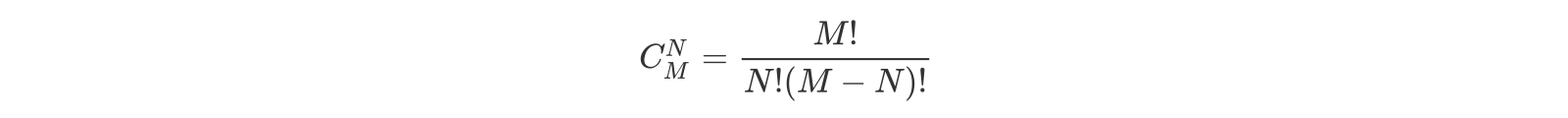
根据我们前面学习的知识,可以用循环做累乘的方式来计算阶乘,那么通过下面的Python代码我们就可以计算出组合数C(M,N)的值,代码如下所示。
1 | """ |
不知大家是否注意到,上面的代码中我们做了三次求阶乘,虽然m、n、m - n的值各不相同,但是三段代码并没有实质性的区别,属于重复代码。世界级的编程大师Martin Fowler先生曾经说过:“代码有很多种坏味道,重复是最坏的一种!”。要写出高质量的代码首先要解决的就是重复代码的问题。那么,在程序中需要反复执行的某些代码,我们能否将他们封装起来呢?答案当时是能,可以使用函数来封装。对于上面的代码来说,我们可以将计算阶乘的功能封装到一个称为“函数”的代码块中,在需要计算阶乘的地方,我们只需要“调用函数”就可以了。关于函数,用一句话总结就是:。简而言之,函数主要扮演两个角色:
最大化的代码复用和最小化代码冗余
Python的函数是一种简黾的办法去打包逻辑算法,使其能够在之后不止在一处、不止一次地使用。直到现在,我们所写的代码都是立即运行的。闲数允i午整合以及通用化代码,以便这些代码能够在之后多次使用。因为它们允许一处编写多处运行,Python的函数是这个语言中婊基本的组成工具一它让我们在程序中减少代码的冗余成为现实,并为代码的维护节省了不少的力气。
1
2
3
4
5
6
7
8
9
10
11
12
13def send_email():
# 10行代码
print("欢迎使用计算机监控系统")
if CPU占用率 > 90%:
send_email()
if 硬盘使用率 > 99%:
send_email()
if 内存使用率 > 98%:
send_email()
...
流程的分解
函数也提供了一种将一个系统分割为定义完好的不同部分的工具。例如,去做一份比萨,开始需要混合面粉,将面粉搅拌幻,增加顶部原料和烤等。如果你是在编写一个制作比萨的机器人的程序,函数将会将整个“做比萨”这个任务分割成为独立的函数来完成整个流程中的每个子任务。独立的实现较小的任务要比一次完成整个流程要容易得多。一般来说,函数汫的是流程:告诉你怎样去做某寧,而不是让你使用它去做某事。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37def calculate_same_num_rule():
"""判断是否是豹子"""
pass
def calculate_same_color_rule():
"""判断是否是同花"""
pass
def calculate_straight_rule():
"""判断是否顺子"""
pass
def calculate_double_card_rule(poke_list):
"""判断是否对子"""
pass
def calculate_single_card_rule():
"""判断是否单牌"""
pass
def generate_cards():
card_color_list = ["红桃", "黑桃", "方片", "梅花"]
card_nums = [2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14] # A
all_card_list = [[color, num] for color in card_color_list for num in card_nums]
return all_card_list
# 1. 生成一副扑克牌
cards_list = generate_cards()
# 2.洗牌
random.shuffle(card_list)
# 3.给玩家发牌
...
# 4.判断牌是:豹子?同花顺?顺子?对子?单点?
calculate_same_num_rule()
calculate_same_color_rule()
calculate_straight_rule()
...
函数具有函数名、参数和返回值。Python中的函数和灵活:可以在模块中但是类之外进行定义,作用域是当前模块,我们称之为函数;也可以在别的函数中定义,我们称之为嵌套函数;还可以子啊类中定义,我们称之为方法。在本部分,我们将会探索在Python中如何编写函数,以及函数所涉及的参数传递、变量作用域等知识点的基本概念和应用。以前我们变成是按照业务逻辑从上到下逐步完成,称为:面向过程编程;现在学了函数之后,利用函数编程称为:函数式编程。那么,让我们开始吧!
二、定义函数
数学上的函数通常形如y = f(x)或者z = g(x, y)这样的形式,在y = f(x)中,f是函数的名字,x是函数的自变量,y是函数的因变量;而在z = g(x, y)中,g是函数名,x和y是函数的自变量,z是函数的因变量。Python中的函数跟这个结构是一致的,每个函数都有自己的名字、自变量和因变量。我们通常把Python中函数的自变量称为函数的参数,而因变量称为函数的返回值。因此,早Python中创建一个函数,需要选择函数名,并定义七参数、行为和返回值。下面是定义函数的语法:
1 | def 函数名(形式参数列表): |
关键字def告诉Python操作者正在定义一个函数。在def关键字后面,指定函数的名称,名称选择遵循与变量名相同的规则。按惯例,函数名不应使用大写字母,应使用单词的小写字母,多个单词之间用下划线分割。命名函数之后,在名称后加上一对圆括号,圆括号中则是希望函数接收的参数。在圆括号之后加入冒号(注意一定是在英文输入法状态下输入的冒号)然后换行并缩进4个空格符(和其他复合语句一样),冒号之后所有缩进4个空格符的代码,就是函数执行的代码块,包含函数体和返回值两部分,函数执行完成后我们会通过return关键字来返回函数的执行结果,就是我们刚才说的函数的因变量,如果没有数据返回,则可以省略return语句。如果函数中没有return语句,那么函数默认返回代表空值的None。另外,在定义函数时,函数也可以没有自变量,但是函数名后面的圆括号是必须有的。
三、函数参数
由于定义函数是的参数不是实际数据,会在调用函数时传递给他们实际数据,所以我们称定义函数时的参数为形式参数,简称形参;称调用函数时传递的实际参数为实际参数,简称实参。你可以将形参理解为在参数中定义的变量。Python中的参数有三种,分别为必选参数(位置参数)、可选参数(缺省参数/默认参数/关键词参数)和不定长参数。
1. 必选参数
必选参数也称位置参数或普通参数,当用户调用函数时,必须传入所有的必选参数,否则Python将引发异常错误。
1 | def rect_area(width, height): |
给函数传参
在定义好函数后,就可以调用函数了,对于有参数的函数,我们需要给给函数传递参数。有两种传参的方式:
使用位置参数给函数传参
在调用函数时传递的实参与定义函数时的形参顺序一致,这是传参的基本形式。
1
2
3
4
5
6def rect_area(width, height): # 形参列表
area = width * height
return area
r_area = rect_area(320, 480) # 实参列表,顺序必须于形参一致
print(f'320 × 480 长方形的面积为:{r_area}')输出
1
320 × 480 长方形的面积为:153600
使用关键字参数给函数传参
在调用函数时可以采用“关键字=实参”的形式,其中,关键字的名称就是定义函数时形参的名称,实参不再受形参的顺序限制。
1
2
3
4r_area = rect_area(width=320, height=480) # 关键字的名称就是定义函数时形参的名称
print(f'320 × 480 长方形的面积为:{r_area}')
r_area = rect_area(width=320, height=480) # 实参不再受形参的顺序限制
print(f'320 × 480 长方形的面积为:{r_area}')输出
1
2320 × 480 长方形的面积为:153600
320 × 480 长方形的面积为:153600使用关键字参数给函数传参时,调用者能够清晰地看出所传递参数的含义,提高函数调用的可读性。
2. 可选参数
在C语言中有函数重载的概念,即可定义多个同名函数,但是参数列表不同,这样在调用时可以传递不同的实参,但是函数重载会增加代码量,所以Python中没有函数重载的概念,而是为函数的参数提供默认值实现的。
可选参数又称缺省参数或关键字参数,Python中还允许函数的参数拥有默认值,必须一个人喜欢喝卡布奇诺,那么卡布奇诺就是他喝咖啡的默认值。
1 | def make_coffee(name='卡布奇诺'): |
我们可以把“CRAPS赌博游戏”的摇色子获得点数的功能封装成函数,代码如下所示。
1 | """ |
我们再来看一个更为简单的例子。
1 | def add(a=0, b=0, c=0): |
注意:带默认值的参数必须放在不带默认值的参数之后,否则将产生
SyntaxError错误,错误消息是:non-default argument follows default argument,翻译成中文的意思是“没有默认值的参数放在了带默认值的参数后面”。
3. 可变参数
Python中的函数可以定义接收不确定数量的参数,这种参数被称为可变参数。可变参数有两种,分别为基于元组的可变参数(参数前加*)和基于字典的可变参数(参数前加**)。
3.1 基于元组的可变参数(*可变参数)
*可变参数在函数中被组装成一个元组,接下来,我们还可以实现一个对任意多个数求和的sum_of_nums函数,因为Python语言中的函数可以通过星号表达式语法来支持可变参数。所谓可变参数指的是在调用函数时,可以向函数传入0个或任意多个参数。将来我们以团队协作的方式开发商业项目时,很有可能要设计函数给其他人使用,但有的时候我们并不知道函数的调用者会向该函数传入多少个参数,这个时候可变参数就可以派上用场。下面的代码演示了用可变参数实现对任意多个数求和的sum_of_nums函数。示例如下:
1 | # 用星号表达式来表示args可以接收0个或任意多个参数 |
3.2 基于字典的可变参数(**可变参数)
**可变参数在函数中被组装成一个字典。示例代码如下:
1 | def show_info(**info): |
我们在设计函数时,如果既不知道调用者会传入的参数个数,也不知道调用者会不会指定参数名,那么同时使用可变参数和关键字参数。关键字参数会将传入的带参数名的参数组装成一个字典,参数名就是字典中键值对的键,而参数值就是字典中键值对的值,代码如下所示。
1 | def sum_of_nums(*args, **kwargs): |
提示:不带参数名的参数(位置参数)必须出现在带参数名的参数(关键字参数)之前,否则将会引发异常。例如,执行
calc(1, 2, c=3, d=4, 5)将会引发SyntaxError错误,错误消息为positional argument follows keyword argument,翻译成中文意思是“位置参数出现在关键字参数之后”。
四、函数返回值
到目前为止,我们创建的函数都只是对传入的数据进行了处理,处理完了就结束。但实际上,在某些场景中,我们还需函数将处理的结果反馈回来,就好像主管向下级员工下达命令,让其去打印文件,员工打印好文件后并没有完成任务,还需要将文件交给主管。
现实生活中的场景:
我给儿子10块钱,让他给我买包烟。这个例子中,10块钱是我给儿子的,就相当于调用函数时传递到参数,让儿子买烟这个事情最终的目标是,让他把烟给你带回来然后给你对么,,,此时烟就是返回值
开发中的场景:
定义了一个函数,完成了获取室内温度,想一想是不是应该把这个结果给调用者,只有调用者拥有了这个返回值,才能够根据当前的温度做适当的调整
综上所述,所谓“返回值”,就是程序中函数完成一件事情后,最后给调用者的结果。返回的作用有两个:结束函数调用和返回值。
1. 返回值语法
Python中,用 def 语句创建函数时,可以用 return 语句指定应该返回的值,该返回值可以是任意类型。需要注意的是,return 语句在同一函数中可以出现多次,但只要有一个得到执行,就会直接结束函数的执行。
函数中,使用 return 语句的语法格式如下:
1 | return [返回值] |
指定返回值与隐含返回值:
- 函数中可以用return关键字加具体的参数表示指定返回值。
- 函数体中没有return语句时,函数运行结束会隐含返回一个None作为返回值,类型是
NoneType,与return 、return None 等效,都是返回 None。
2. 返回单个值
请看下面示例:
1 | def add(a,b): |
本例中,add() 函数既可以用来计算两个数的和,也可以连接两个字符串,它会返回计算的结果。通过 return 语句指定返回值后,我们在调用函数时,既可以将该函数赋值给一个变量,用变量保存函数的返回值,也可以将函数再作为某个函数的实际参数。
1 | def isGreater0(x): |
可以看到,函数中可以同时包含多个 return 语句,但需要注意的是,最终真正执行的做多只有 1 个,且一旦执行,函数运行会立即结束,return之后的其它语句都不会被执行了。
3. 返回多个值
函数返回值的注意事项: 不同于 C 语言,Python 函数可以返回多个值,多个值以元组的方式返回。
1 | def fun(a,b): |
4. 返回值小结
了解了函数返回值的使用之后,再来看一下三个重要的知识点:
返回值可以是任意类型,如果函数中没写return,则默认返回None
1
2
3
4
5def func():
return [1,True,(11,22,33)]
result = func()
print(result)1
2
3
4
5def func():
value = 1 + 1
ret = func()
print(ret) # None当在函数中
未写返回值或return或return None,执行函数获取的返回值都是None。1
2
3
4
5
6def func():
value = 1 + 1
return # 或 return None
ret = func()
print(ret) # Nonereturn后面的值如果有逗号,则默认会将返回值转换成元组再返回。
1
2
3
4
5def func():
return 1,2,3
value = func()
print(value) # (1,2,3)函数一旦遇到return就会立即退出函数(终止函数中的所有代码)
1
2
3
4
5
6
7def func():
print(1)
return "结束吧"
print(2)
ret = func()
print(ret)1
2
3
4
5
6
7
8
9
10
11
12
13
14def func():
print(1)
for i in range(10):
print(i)
return 999
print(2)
result = func()
print(result)
# 输出
1
0
9991
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def func():
print(1)
for i in range(10):
print(i)
for j in range(100):
print(j)
return
print(2)
result = func()
print(result)
# 输出
1
0
0
None
返回值应用场景:
完成某个结果并希望的到结果。
1
2
3
4
5def send_email():
...
return True
v1 = send_email()1
2
3
4
5
6def encrypt(old):
...
return "密文..."
data = encrypt("张亚飞")
print(data)基于return控制让函数终止执行
1
2
3
4
5
6
7
8
9
10
11def func(name):
with open("xxx.txt",mode='r',encoding="utf-8") as file_object:
for line in file_object:
if name in line:
return True
data = func("张亚飞")
if data:
print("存在")
else:
print("不存在")1
2
3
4
5
6
7
8
9
10
11
12
13def foo():
while True:
num = input("请输入数字(Q):")
if num.upper() == "Q":
return
num = int(num)
if num == 99:
print("猜对了")
else:
print("猜错了,请继续!")
print("....")
foo()
根据有无参数和返回值,函数可以分为以下四种:
无参数,无返回值
1
2def func():
...无参数,有返回值
1
2
3def func():
...
return 返回值有参数,无返回值
1
2def func(参数):
...有参数,有返回值
1
2def func(参数):
return 返回值
五、示例代码重构
我们可以通过函数对本节开始的代码进行重构。所谓重构,是在不影响代码执行结果的前提下对代码的结构进行调整。重构之后的代码如下所示。
1 | """ |
六、函数注释
函数参数又称文档字符串DocStrings,DocStrings 文档字符串是一个重要工具,用于解释文档程序,帮助你的程序文档更加简单易懂。我们可以在函数体的第一行使用一对三个单引号 ‘’’ 或者一对三个双引号 “”” 来定义文档字符串。你可以使用 doc(注意双下划线)调用函数中的文档字符串属性。
1 | def sum_of_nums(*args, **kwargs): |
七、用模块管理函数
对于任何一种编程语言来说,给变量、函数这样的标识符起名字都是一个让人头疼的问题,因为我们会遇到命名冲突这种尴尬的情况。最简单的场景就是在同一个.py文件中定义了两个同名函数,由于Python没有函数重载的概念,那么后面的定义会覆盖之前的定义,也就意味着两个函数同名函数实际上只有一个是存在的。
1 | def foo(): |
当然上面的这种情况我们很容易就能避免,但是如果项目是由多人协作进行团队开发的时候,团队中可能有多个程序员都定义了名为foo的函数,那么怎么解决这种命名冲突呢?答案其实很简单,Python中每个文件就代表了一个模块(module),我们在不同的模块中可以有同名的函数,在使用函数的时候我们通过import关键字导入指定的模块就可以区分到底要使用的是哪个模块中的foo函数,代码如下所示。
module1.py
1 | def foo(): |
module2.py
1 | def foo(): |
test.py
1 | from module1 import foo |
也可以按照如下所示的方式来区分到底要使用哪一个foo函数。
test.py
1 | import module1 as m1 |
但是如果将代码写成了下面的样子,那么程序中调用的是最后导入的那个foo,因为后导入的foo覆盖了之前导入的foo。
test.py
1 | from module1 import foo |
test.py
1 | from module2 import foo |
需要说明的是,如果我们导入的模块除了定义函数之外还中有可以执行代码,那么Python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些执行代码放入如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是”__main__“。
module3.py
1 | """ |
test.py
1 | import module3 |
八、变量的作用域
变量有一个很重要的属性,作用域(scope)。在定义变量时,其作用变量是哪部分程序可以对其进行读写,读取一个变量意味着获取它的值,写变量意味着修改它的值,变量的作用域由其定义在程序中所处的位置决定。
如果在函数(或类,面对对象部分会介绍)之外定义了一个变量,则变量拥有全局作用域(global scope):即程序在任意地方都可以对其进行读写操作。带有全局作用域的全量,被称为全局变量(global variable)。如果在函数(或类)内部定义一个变量,则变量拥有局部作用域(local scope):即程序只有在定义该变量的函数内部才可对其进行读写。下面示例中的变量拥有全局作用域:
1 | x = 1 |
这些变量不是在函数(或类)内部定义的,因此拥有全局作用域。这意味着可以在程序的任意地方对其进行读写,包含在函数内部。示例如下:
1 | x = 2 |
如果是在函数内部定义的这些变量,则只能在那个函数内部对其进行读写。如果尝试在该函数之外访问他们,则Python会报异常错误。示例如下:
1 | def f(): |
如果在函数内部定义这些变量,则会成功运行。示例如下:
1 | def f(): |
在定义变量的函数之外使用变量,相当于使用一个尚未定义的变量,二者都会使Python报告相同的异常错误:
1 | if x > 100: |
可以在程序的任何地方对全局变量进行写操作,但是在局部作用域中需稍加注意:必须明确使用global关键字,并在其后写上希望修改的变量。Python要求这样做,是为了确保在函数内部定义变量x时,不会意外变更之前在函数外部定义的变量的值。在函数内部对全局变量进行写操作的示例如下:
1 | x = 100 |
没有作用域,则可以在程序任何地方访问所有变量,这样会造成很大的问题。如果程序代码量很大,其中有一个使用变量x的函数,你可能会在其他地方修改该变量的值。类似这样的错误会改变程序的行为,并导致意料之外的结果。程序规模越大,变量数量越多,出现问题的可能性就越高。
我们再来看一个例子:
1 | def foo(): |
上面的代码能够顺利的执行并且打印出100、hello和True,但我们注意到了,在bar函数的内部并没有定义a和b两个变量,那么a和b是从哪里来的。我们在上面代码的if分支中定义了一个变量a,这是一个全局变量(global variable),属于全局作用域,因为它没有定义在任何一个函数中。在上面的foo函数中我们定义了变量b,这是一个定义在函数中的局部变量(local variable),属于局部作用域,在foo函数的外部并不能访问到它;但对于foo函数内部的bar函数来说,变量b属于嵌套作用域,在bar函数中我们是可以访问到它的。bar函数中的变量c属于局部作用域,在bar函数之外是无法访问的。事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些标识符,我们之前用过的input、print、int等都属于内置作用域。
1. 作用域法则
函数提供了嵌套的命名空间(作用域),使其内部使用的变量名本地化,以便函数内部使用的变量名不会与函数外(在一个模块或是其他函数中)的变量名产生冲突。再一次说明,函数定义了本地作用域,而模块定义的是全局作用域。这两个作用域有如下关系:
- 内嵌的模块是全局作用域。
- 全局作用域的作用范围仅限于单个文件。
- 每次对函数的调用都创建了一个新的本地作用域。
- 赋值的变量名除非声明为全局变量或非本地变量,否则均为本地变量。如果需要给一个函数内部却位于模块文件顶层的变量名赋值。需要在函数内部通过
global语句声明。如果需要给位于一个嵌套的函数中的变量赋值,可以通过nonlocal语句声明它来做到。 - 所有其他的变量名都可以规划为本地、全局或者内置的。
2. 变量名解析:LEGB原则
如果上一节的内容看起来有些令人困惑的话,我们总结这样三条简单的原则。对于一个函数:
- 变鼋名引用分为三个作用域进行查找:首先是本地,之后是函数内(如果有的话),之后仝局,最后是内置。
- 在默认情况下、变量名賦值会创建或改变本地变量。
- 全局声明和非本地声明将賦值的变敏名映射到模块文件内部的作用域。
换句话说,所有在函数内赋值的变量名均默认为本地变量。函数能够在函数以及全局作用域直接使用变量名,但是必须声明为非本地变量和全局变量去改变其属性。
Python的变杖名解析机制有时称为LEGB法则,这也是由作川域的命令而来的。
- 当在函数中使用未认证的变量名时,Python搜索4个作用域【本地作用域(L),之后是在上一层结构中def或lambda的本地作川城(E》,之后是全局作用城(G),最后是内置作用城(B)】并且在第一处能够找到这个变敬名的地方停下来。如果变量名在这次搜索中没有找到,Python会报错.变量名在使用前首先必须赋值过。
- 当在函数中给一个变最名赋值时(而不是在一个表达式中对其进行引川),Python总是创建或改变本地作用域的变量名,除非它已经在那个函数中声明为全局变敬。
- 当在函数之外给~个变量名赋值时(也就是,在一个模块文件的顶层,或者是在交互提示模式下),本地作川城与全局作用城(这个模块的命名空间)是相同的。
3. 内置作用域
内置作用域其实很简单,我们恶意通过builtins来查看。
1 | import builtins |
输出
1 | ['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip'] |
4. global语句
global关键字是一个命名空间的声明,他告诉Python函数打算生成一个或多个全局变量名。再看看下面这段代码,我们希望通过函数调用修改全局变量x的值,但实际上下面的代码是做不到的。
1 | # 创建全局变量x,作用域是整个模块 |
此时,我们可以使用global关键字
1 | # 创建全局变量x,作用域是整个模块 |
在这个例子中我们增加了一个global声明,以便在函数之内的x能够引用全局变量x,从而达到修改全局变量的目的。注意y和z并没有进行global声明,Python的LEGB查找法则将会自动从模块中找到他们·。我们可以使用global关键字来指示print_value函数中的变量x来自于全局作用域,如果全局作用域中没有x,那么下面一行的代码就会定义变量x并将其置于全局作用域。同理,如果我们希望函数内部的函数能够修改嵌套作用域中的变量,可以使用nonlocal关键字来指示变量来自于嵌套作用域。
5. nonlocal语句
nonlocal语句时global的近亲,和global不同的是,nonlocal应用于一个嵌套的函数的作用域中的一个变量,而不是所有函数之外的全局作用域;而且在声明nonlocal关键字时,他必须已经存在于该嵌套函数的作用域中,他们可能只存在于一个嵌套的函数中,并且不能由一个嵌套的函数中第一次赋值创建。
1 | count = 1 |
该代码就可以很好的解释了,第一行的count和a()函数中的count是两个变量,而a()函数中的count变量只是在该函数内部起作用,因为它是一个局部变量。nonlocal只能在封装函数中使用,在外部函数先进行声明,在内部函数进行nonlocal声明,这样在b()函数中的count与a()中的count是同一个变量。下面我们来看一个nonlocal的错误使用方法
1 | count = 1 |
在实际开发中,我们应该尽量减少对全局变量的使用,因为全局变量的作用域和影响过于广泛,可能会发生意料之外的修改和使用,除此之外全局变量比局部变量拥有更长的生命周期,可能导致对象占用的内存长时间无法被垃圾回收。事实上,减少对全局变量的使用,也是降低代码之间耦合度的一个重要举措,同时也是对迪米特法则的践行。减少全局变量的使用就意味着我们应该尽量让变量的作用域在函数的内部,但是如果我们希望将一个局部变量的生命周期延长,使其在定义它的函数调用结束后依然可以使用它的值,这时候就需要使用闭包,这个我们在后续的内容中进行讲解。
说了那么多,其实结论很简单,从现在开始我们可以将Python代码按照下面的格式进行书写,这一点点的改进其实就是在我们理解了函数和作用域的基础上跨出的巨大的一步。
1 | def main(): |
九、内置函数
Python标准库中提供了大量的模块和函数来简化我们的开发工作,我们之前用过的random模块就为我们提供了生成随机数和进行随机抽样的函数;而time模块则提供了和时间操作相关的函数;上面求阶乘的函数在Python标准库中的math模块中已经有了,实际开发中并不需要我们自己编写,而math模块中还包括了计算正弦、余弦、指数、对数等一系列的数学函数。随着我们进一步的学习Python编程知识,我们还会用到更多的模块和函数。
Python标准库中还有一类函数是不需要import就能够直接使用的,我们将其称之为内置函数,这些内置函数都是很有用也是最常用的,下面的表格列出了一部分的内置函数。
| 函数 | 说明 |
|---|---|
abs |
返回一个数的绝对值,例如:abs(-1.3)会返回1.3。 |
bin |
把一个整数转换成以'0b'开头的二进制字符串,例如:bin(123)会返回'0b1111011'。 |
chr |
将Unicode编码转换成对应的字符,例如:chr(8364)会返回'€'。 |
hex |
将一个整数转换成以'0x'开头的十六进制字符串,例如:hex(123)会返回'0x7b'。 |
input |
从输入中读取一行,返回读到的字符串。 |
len |
获取字符串、列表等的长度。 |
max |
返回多个参数或一个可迭代对象(后面会讲)中的最大值,例如:max(12, 95, 37)会返回95。 |
min |
返回多个参数或一个可迭代对象(后面会讲)中的最小值,例如:min(12, 95, 37)会返回12。 |
oct |
把一个整数转换成以'0o'开头的八进制字符串,例如:oct(123)会返回'0o173'。 |
open |
打开一个文件并返回文件对象(后面会讲)。 |
ord |
将字符转换成对应的Unicode编码,例如:ord('€')会返回8364。 |
pow |
求幂运算,例如:pow(2, 3)会返回8;pow(2, 0.5)会返回1.4142135623730951。 |
print |
打印输出。 |
range |
构造一个范围序列,例如:range(100)会产生0到99的整数序列。 |
round |
按照指定的精度对数值进行四舍五入,例如:round(1.23456, 4)会返回1.2346。 |
sum |
对一个序列中的项从左到右进行求和运算,例如:sum(range(1, 101))会返回5050。 |
type |
返回对象的类型,例如:type(10)会返回int;而type('hello')会返回str。 |
十、简单总结
函数是功能相对独立且会重复使用的代码的封装。学会使用定义和使用函数,就能够写出更为优质的代码。当然,Python语言的标准库中已经为我们提供了大量的模块和常用的函数,用好这些模块和函数就能够用更少的代码做更多的事情。
