001-文件管理
通配符
1 | *:匹配0或多个字符 |
字符串
1 | 1、字符串或串(String)是由数字、字母、下划线组成的一串字符。一般记为 s=“a1a2···an”(n>=0)。它是编程语言中表示文本的数据类型。在程序设计中,字符串(string)为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字)。 |
ASCII比较大小
1 | ASCII比较大小的时候,是比较两个数中的第一个字符 |
cat
1 | 突破 |
grep
1 | -w 完全匹配 |
1 | 报错Binary file (standard input) matches: |
find
1 | 删除多少天之前的文件 |
rm删除文件不释放
1 | 解决linux删除文件后空间没有释放问题 |
shuf命令
1 | shuf命令把输入行按随机顺序输出到标准输出。 |
grep 和 awk的buffer
1 | tail -f test.log | grep "mode" | awk '{print $5}'命令 |
sed
1 | https://www.cnblogs.com/fiberhome/p/6898786.html |
awk
在使用awk处理内容时,有时会按行执行Linux命令,下面介绍两种执行Linux命令方式。
方式一:用system():
1 | [root@localhost shell_script]# awk 'BEGIN {system("pwd")}' |
test.log文件:
1 | [root@localhost shell_script]# cat test.log |
按文件行作为输入执行:
$0 表示一行数据
1 | [root@localhost shell_script]# awk '{print "执行命令:"$0; system($0); print "\r"}' test.log |
拼接命令:
1 | [root@localhost shell_script]# echo "sh601236" | awk '{cmd = "curl -X GET http://hq.sinajs.cn/list="$0; system(cmd);}' |
方式二:借助|和sh命令:
1 | [root@localhost shell_script]# echo "pwd" | sh |
1 | [root@localhost shell_script]# awk 'BEGIN {print "pwd" | "sh"}' |
1 | https://www.cnblogs.com/xudong-bupt/p/3721210.html |
split
1 | split -b 10k date.file -d -a 3 |
qemu-img
1 | qemu-img convert -S 8k -f qcow2 CentOS7U3_GLOBAL_64bit_75G_20180404_APP.qcow2 -O raw /dev/sdc1 ----直接将qcow2文件转换并写入sdc1磁盘,记得设置-S 8k ---这个参数指定稀疏拷贝,只写有效数据@王星童 |
dd
1 | if是来源,of是目的。 |
tr:去除字母
1 | cat file | tr -d "a-zA-Z">new_file |
column :对齐
1 | 以将文本结果转换为整齐的表格,上下对齐 |
stat:文件的状态信息
1 | stat命令文件权限属性设置 |
paste -d,
1 | [root102442549 ChunkServer]# cat /etc/snbs.conf.back|grep -E "VolDev"|awk -F = '{print $2}'|sed 's/,/\n/g' |
sort:排序
1 | 去除重复行 |
1 | 按数字排序:sort -n number.txt |
1 | [root@snbs161-201-instance opt]# head stat.log |
map:键值
1 | 读文件放到map中: |
002-磁盘管理
查看磁盘分区UUID的四种方法
1 | 1、使用/dev/disk/by-uuid目录 |
如何关闭硬盘写缓存(Write Cache)
1 | http://ilinuxkernel.com/?p=897 |
Linux创建虚拟块设备并格式化为文件系统
1 | https://blog.csdn.net/q1449516487/article/details/100518520 |
1 | 关于回环设备是什么可以参考如下解释: |
1 | 1. 什么是loop设备? |
lvm
1 | raid卡是提高性能的 |
1 | 磁盘 |
1 | https://blog.csdn.net/qq_27721925/article/details/52403912 |
1 | linux环境下,假设有一个磁盘/dev/vdb(ssd磁盘可能是sda或者sdb),一共200G, 要将其分为3个逻辑分区,分别挂载在/mysql, /binlog, /bak三个目录下 |
part
1 | https://blog.csdn.net/qq_32863631/article/details/76047133 |
fdisk
1 | [root@host102442553 ~]# fdisk /dev/sdc |
1 | https://www.cnblogs.com/zishengY/p/7137671.html |

1 | 输入p 查看当前硬盘分区,目前没有分区 |

1 | 输入n新建一个分区,输入p 建立分区,输入分区编号 1 |

1 | 然后会让你设置开始扇区,我填的是开始扇区2048,结束,20480 |

1 | 可以填“+100G” |

1 | 其实这个时候,建立好的分区还不能用,还需要挂载才可以用。但是挂载之前,必须要格式化,才行。。。 |
MBR和GPT
1 | 模拟磁盘损坏: |
惰性初始化
1 | mount的时候: |
raid卡
1 | 参考博客: |
1 | raid卡是提高性能的 |
1 | 查看是否带raid卡:udevadm test-builtin blkid "$device" 2>/dev/null | grep -q "^ID_FS_USAGE=raid" |
1 | /opt/zabbix/lldscripts/MegaRAID/MegaCli/MegaCli64 -AdpAllInfo -a0|grep Policy |

应该是内核开的,我记得以前默认都是关闭的,
厂家回复:
storcli64
1 | 1、简介(软件见附件) |
MegaCli
1 | MegaCli使用参考文档(版本包见附件) |
去除raid 0
1 | 1.BMC进入设备终端 |
3.启动过程中执行:ctrl+r 进入raid模式

4.选中RAID 0,按F2,选中Delete Drive Group,按enter选择YES,确认删除


5.按Ctrl+N进入下一页,TAB选择到JBOD,按空格勾选(x),下图是没勾选,选择apply提交


6.以及按Ctrl+p向前查看磁盘是否都做了jbod
查看磁盘型号
1 | smartctl --all /dev/sda |
003-网络
时间同步及设置ip
1 | 服务器时间同步: |
centos关闭防火墙
1 | CentOS7用firewall命令“替代”了iptables。 |
ping
1 | 需要使用ping命令的-c参数和-s参数,其含义如下: |
telnet
1 | 情景 |
ssh
1 | vdbench免密拷机的时候,会无缘无故的退出,之后发现ssh超时,需要注释下面两行,重启sshd |
1 | 增加ssh连接数: |
1 | 远程到另外一台linux设备并执行命令: |
sshpass
1 | # yum -y install sshpass |
scp
1 | 远程拷贝:scp -r -P PORT /home/setup root@80.80.45.37:/home/setup(-P PORT为指定端口) |
双网卡配置
1 | 9。双网卡配置: |
设备重启后网口变了
1 | 压测环境: |
路由
1 | 有的端口不是默认的 |
004-调试命令
watch
1 | watch "ls -lh snbs.bin" |
1 | linux watch 命令使用;进行循环执行程序,并显示结果;https://www.cnblogs.com/xuyaowen/p/watch-proc.html |
screen
1 | 5.4 会话分离与恢复 |
curl
1 | shell脚本curl命令,会出现有些链接,链接不上的问题: |
1 | curl 带-w "%{http_code}"这个参数直接返回 |
dmesg
1 | 命令:dmesg |
tc命令
1 | 1 模拟延迟传输简介 |
1 | Linux 中模拟延时和丢包的实现 |
长短链接
1 | 1、长短链接 |

内存泄露
1 | [root@sdosspststorage10 my]# ps -ef|grep fuse|grep -v grep |
005-字符串
1 | echo是没有opone的 |
字符串大小写转换
1 | https://www.cnblogs.com/loveyouyou616/p/10416507.html |
shuf命令
1 | shuf命令把输入行按随机顺序输出到标准输出。 |
Linux 的字符串截取
1 | https://www.cnblogs.com/shizhijie/p/8297840.html |
006-数据库
mysql
1 | select * from filemap limit 1\G |
1 | 8.show slave status命令可以显示主从同步的状态 |
1 | .如何判断mysql是否有延迟: |
1 | 查看mysql连接数: |
mysql倒序:
1 | select * from measure_ottcache_error_5minutes_data order by stattime desc limit 10; |
redis
1 | 5.redis密码: |
007-系统
windows
1 | cmd计算器:calc |
last
1 | last 命令介绍 |
时间同步
1 | chrond |
1 | ntpdate |
自定义linux命令
1 | 6、linux命令: |
关闭swap
1 | 1.关闭swap: |
/etc/rc.local:开机执行
1 | 将脚本执行命令:/etc/rc.local里,开机自动执行 |
系统配置
1 | 一些常识背景: |
系统参数
1 | [root@ceph1 limits.d]# cat /etc/security/limits.d/20-nproc.conf |
dsa免密
1 | 使用dsa方式免密能解决: |
免密登录脚本
1 | serverlist.txt文件写具体的ip地址 |
rsa免密登录
1 | ssh-keygen -t rsa |
1 | serverlist.txt文件写具体的ip地址 |
1 | serverlist.txt文件写具体的ip地址 |
查看系统版本
1 | cat /etc/redhat-release |
虚机卡执行
1 | echo 204800 > /proc/sys/vm/min_free_kbytes |
fuser
1 | 查看哪个进程在写文件 |
isof
1 | isof: |
ulimit
1 | ulimit -c |
date
1 | 获取前7天的日期:date +%Y%m%d --date="-7 day" |
ntp
1 | ntp:[root@ceph2 tool]# crontab -l |
logrotate
1 | 1、关于日志切割 |
清理设备所有缓存
1 | 清理所有缓存:echo 3 > /proc/sys/vm/drop_caches |
yum
1 | 执行yum install openjdk.x86_64 –y报错: |
执行jar包
1 | storm jar stormkafka-0.0.1.jar suning.oss.stat.RollingNginxTopWords 10.27.38.33 |
重启nginx
1 | /opt/tengine/sbin/nginx -s quit 停止nginx |
jdk
1 | mkdir -p /usr/local/java/;tar -vzxf jdk-8u181-linux-x64.tar.gz -C /usr/local/java/ |
nmon
1 | 参考网址: |
ftp
1 | 1、yum install vsftpd |
lrzsz
1 | 安装方法: |
清屏
1 | cls 清屏 |
008-性能
top
1 | top -p 4078 -n 1 只打印一次 |
iostat
1 | io |
查看当前占用最多的K个进程
1 | https://www.cnblogs.com/nulige/p/8439231.html |
vmstat+iostat
1 | 监控cpu和内存--vmstat 2 |
009-异常模拟
cpu模拟
1 | [Linux运维]常用场景模拟 -- cpu使用率模拟 |
网络异常
1 | iptables -I INPUT -s 10.27.38.241 -j DROP |
消耗内存
1 | [root@ceph1 tool]# cat eatMem.c |
模拟丢包
1 | cat /proc/cpuinfo |grep "physical id" | wc -l 可以获得CPU的个数, 我们将其表示为N. |
ASM磁盘头信息损坏和修复(kfed/dd)
1 | https://blog.csdn.net/zhengwei125/article/details/50836329 |
010-其他
rz命令安装
1 | rpm -ivh rzsz-0.12.20-934.22.x86_64.rpm |
Wireshark
001-庖丁解牛
1 | tcpdump -i any host 80.80.46.76 -w target.cap |
1.只抓包头:
1 | tcpdump -i eth0 -s 80 -w tcpdump.cap |
2.只抓必要的包
1 | tcpdump -i eth0 host 10.32.200.131 -w tcpdump.cap |
3.过滤
1 | ip.addr eq 10.32.106.50 && tcp.port eq 8080 |
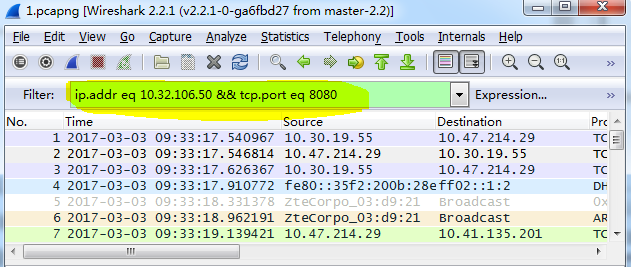
1 | 如果已知某个协议发生为题可以用协议名称过滤一下。 |
4.让Wireshark自动分析
1 | 单击Wireshark的Analyze-->Expert Info Composite在分析网络性能和连接问题时,借助此功能 |
5.搜索功能
1 | Ctrl+F后选中“String”单选按钮搜索关键字,在Filter中输入例如:error |
011-SHELL
1 | break(循环控制) |
小数和整数比较
1 | https://www.cnblogs.com/shixun/p/6179642.html |
read
1 | 情景 |
EOT、EOF
1 | EOT:EOT是“end of file”,表示文本结束符。即可避免使用多行echo命令的方式,并实现多行输出的结果。 |
exec
1 | 懒的整理:http://xstarcd.github.io/wiki/shell/exec_redirect.html |
$
1 | $0: 脚本本身文件名称 |
printf
1 | printf |
shift:参数左移
1 | shell脚本shfit |
1 | shift命令用于对参数的移动(左移),通常用于在不知道传入参数个数的情况下依次遍历每个参数然后进行相应处理(常见于Linux中各种程序的启动脚本)。 |
readlink
1 | 全路径文件名/dirname:文件所在的目录 |
random:从数组中随机抽取元素
1 |
|
getopt
1 | getopt(一个外部工具) |
eval
1 | https://www.cnblogs.com/f-ck-need-u/p/7426371.html |
exit
1 | exit(0):正常运行程序并退出程序; |
运算符
1 | https://www.runoob.com/linux/linux-shell-basic-operators.html |
nohup
1 | nohup ./start.sh >output 2>&1 & |
