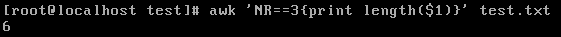前言 awk是linux下的一个命令,他对其他命令的输出,对文件的处理都十分强大,其实他更像一门编程语言,他可以自定义变量,有条件语句,有循环,有数组,有正则,有函数等。他读取输出,或者文件的方式是一行,一行的读,根据你给出的条件进行查找,并在找出来的行中进行操作,感觉他的设计思想,真的很简单,但是结合实际情况,具体操作起来就没有那么简单了。他有三种形势,awk,gawk,nawk,平时所说的awk其实就是gawk。
awk是一个强大的文本分析工具,相对于grep的查找,sed的编辑,awk在其对数据分析并生成报告时,显得尤为强大。简单来说awk就是把文件逐行的读入,以空格为默认分隔符将每行切片,切开的部分再进行各种分析处理。
awk语言的最基本功能是在文件或者字符串中基于指定规则浏览和抽取信息,awk抽取信息后,才能进行其他文本操作。完整的awk脚本通常用来格式化文本文件中的信息。通常,awk是以文件的一行为处理单位的。awk每接收文件的一行,然后执行相应的命令,来处理文本。
逐行处理的意思就是说,当awk处理一个文本时,会一行一行进行处理,处理完当前行,再处理下一行,awk默认以”换行符”为标记,识别每一行,也就是说,awk跟我们人类一样,每次遇到”回车换行”,就认为是当前行的结束,新的一行的开始,awk会按照用户指定的分割符去分割当前行,如果没有指定分割符,默认使用空格作为分隔符。
0表示显示整行,NF表示当前行分割后的最后一列(0和 0和0和NF均为内置变量)注意,NF和NF要表达的意思是不一样的,对于awk来说, $NF 和 NF 要表达的意思是不一样的,对于awk来说,$NF表示最后一个字段,NF表示当前行被分隔符切开以后,一共有几个字段。也就是说,假如一行文本被空格分成了7段,那么NF的值就是7,$NF的值就是$7, 而7表示当前行的第7个字段,也就是最后一列,那么每行的倒数第二列可以写为 7表示当前行的第7个字段,也就是最后一列,那么每行的倒数第二列可以写为7表示当前行的第7个字段,也就是最后一列,那么每行的倒数第二列可以写为(NF-1)。
1.使用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 awk '{pattern + action}' {filenames} 或者 awk 'pattern {action}' {filenames} # 尽管操作可能会很复杂,但语法总是这样; # pattern 表示 AWK 在数据中查找的内容; # action是在找到匹配内容时所执行的一系列命令; # 花括号({})不需要在程序中始终出现,但它们用于根据特定的模式对一系列指令进行分组; # pattern 要表示的正则表达式,用斜杠括起来。 或者 awk [-F|-f|-v] ‘BEGIN{} //{command1; command2} END{}’ file [-F|-f|-v] 大参数,-F指定分隔符,-f调用脚本,-v定义变量,可以进行变量的赋值及调用(调用不需要加$符) var=value ' ' 引用代码块 BEGIN 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符 // 匹配代码块,可以是字符串或正则表达式 {} 命令代码块,包含一条或多条命令 ; 多条命令使用分号分隔 END 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
注1:
1 默认情况下,正则表达式的匹配工作在贪婪模式下,也就是说它会尽可能长地去匹配,比如某一行有字符串 abacb,如果搜索内容为 "a.*b" 那么会直接匹配 abacb这个串,而不会只匹配ab或acb。
注2:
1 所有的正则字符,如 [ 、* 、( 等,若要搜索 * ,而不是想把 * 解释为重复先前字符任意次,可以使用 \* 来转义。
2. 变量
特殊要点:
$0
表示整个当前行
$1
每行第一个字段
NF
字段数量变量
NR
每行的记录号,多文件记录递增
FNR
与NR类似,不过多文件记录不递增,每个文件都从1开始
\t
制表符
\n
换行符
FS
BEGIN时定义分隔符
RS
输入的记录分隔符, 默认为换行符(即文本是按一行一行输入)
~
匹配,与==相比不是精确比较
!~
不匹配,不精确比较
==
等于,必须全部相等,精确比较
!=
不等于,精确比较
&&
逻辑与
||
逻辑或
+
匹配时表示1个或1个以上
/[0-9][0-9]+/
两个或两个以上数字
/[0-9][0-9]*/
一个或一个以上数字
FILENAME
文件名
OFS
输出字段分隔符, 默认也是空格,可以改为制表符等
ORS
输出的记录分隔符,默认为换行符,即处理结果也是一行一行输出到屏幕
-F’[:#/]’
定义三个分隔符
域就是列;
变 量
描述
$n
当前记录的第n个字段,字段间由 FS分隔。
$0
完整的输入记录/整条记录
$1
当前行的第一个域
$NF
是number finally,表示最后一列的信息,跟变量NF是有区别的,变量NF统计的是每行列的总数
ARGC
命令行参数的数目。
ARGIND
命令行中当前文件的位置(从0开始算)。
ARGV
包 含命令行参数的数组/命令行参数排列
CONVFMT
数字转换格式(默认值为%.6g)
ENVIRON
环境变量关联数组/支持队列中系统环境变量的使用
ERRNO
最后一个系统错误的描述。
FIELDWIDTHS
字 段宽度列表(用空格键分隔)。
FILENAME
当前文件名/awk浏览的文件名
FNR
同 NR,但相对于当前文件/浏览文件的记录数
FS
字段分隔符(默认是任何空格)。/设置输入域分隔符,等价于命令行 -F选项
IGNORECASE
如 果为真,则进行忽略大小写的匹配。
NF
当前记录中的字段数/浏览记录的域的个数
NR
当前记录数/已读的记录数
OFMT
数字的输出格式(默认值是%.6g)。
OFS
输出字段分隔符(默认值是一个空格)/输出域分隔符
ORS
输出记录分隔符(默认值是一个换行符)/输出记录分隔符
RLENGTH
由 match函数所匹配的字符串的长度。
RS
记录分隔符(默认是一个换行符)/控制记录分隔符
RSTART
由 match函数所匹配的字符串的第一个位置。
SUBSEP
数组下标分隔符(默认值是\034)。
3. 运算符
运算符
描述
= += -= = /= %= ^= * =
赋值
?:
C条件表达式
||
逻 辑或
&&
逻辑与
~ ~!
匹 配正则表达式和不匹配正则表达式
< <= > >= != ==
关 系运算符
空格
连接
+ -
加,减
* / &
乘,除与求余
+ - !
一元加,减和逻辑非
^ ***
求幂
++ –
增加或减少,作为前缀或后缀
$
字 段引用
in
数组成员
4. awk的正则
匹配符
描述
\Y
匹配一个单词开头或者末尾的空字符串
\B
匹配单词内的空字符串
<
匹配一个单词的开头的空字符串,锚定开始
>
匹配一个单词的末尾的空字符串,锚定末尾
\W
匹配一个非字母数字组成的单词
\w
匹配一个字母数字组成的单词
'
匹配字符串末尾的一个空字符串
'
匹配字符串开头的一个空字符串
5.字符串函数
函数名
描述
sub
匹配记录中最大、最靠左边的子字符串的正则表达式,并用替换字符串替换这些字符串。如果没有指定目标字符串就默认使用整个记录。替换只发生在第一次匹配的 时候
gsub
整个文档中进行匹配
index
返回子字符串第一次被匹配的位置,偏移量从位置1开始
substr
返回从位置1开始的子字符串,如果指定长度超过实际长度,就返回整个字符串
split
可按给定的分隔符把字符串分割为一个数组。如果分隔符没提供,则按当前FS值进行分割
length
返回记录的字符数
match
返回在字符串中正则表达式位置的索引,如果找不到指定的正则表达式则返回0。match函数会设置内建变量RSTART为字符串中子字符串的开始位 置,RLENGTH为到子字符串末尾的字符个数。substr可利于这些变量来截取字符串
toupper和tolower
可用于字符串大小间的转换,该功能只在gawk中有效
以test.txt作为处理对象,内容如下:
1. sub/gsub 替换 用法:sub/gsub(/str1/,str2,col)
str1:要替换成的字符串(用两个正斜杠包裹)
str2:被替换的字符串
col:被处理的列(可省略代表处理当前行)
区别:sub之替换第一次出现的,gsub替换所有
例如替换test.txt文本第一行第一次出现/所有的双引号(”)为星号(*):
1 awk 'NR==1{sub(/"/," *");print $0} ' test .txt
1 awk 'NR==1{gsub(/"/," *");print $0} ' test .txt
2. toupper/tolower 大/小写转换 用法:toupper/tolower(col)
col:被处理的列(不可省略)
例如把test.txt文本中第二行的”ApplE”按全大写、”baNaNa”按全小写输出:
1 awk 'NR==2{print toupper($1 );print tolower($2 )}' test .txt
3. length 获取长度 用法:length(col)
col:被处理的列(可省略代表处理当前行)
例如获取test.txt文本第三行第一列的字段的长度:
1 awk 'NR==3{print length ($1 )}' test .txt
4. substr 截取子串 用法:substr(col,startindex,len)
col:被处理的列(不可省略)
startindex:要截取子串的起始下标(从1开始)
len:要截取子串的长度(值为正整数才有效)
例如截取test.txt文本第三行第二列的字段,从该字段下标为5的位置开始截取4个字符长度
1 awk 'NR==3 {print substr($2 ,5 ,4 )}' test.txt
5. index/match 获取位置(第一次出现) 用法:index/match(col,str)
col:被处理的列(不可省略)
str:匹配的字符串/正则表达式
区别:index匹配的是字符串,match匹配的是正则表达式,此外针对match方法,awk还有两个内置变量RSTART、RLENGTH
RSTART:同index/match命令的返回值,正则表达式匹配的字符串在原列中第一次出现位置(下标从1开始,无匹配返回0)
RLENGTH:正则表达式匹配的字符串长度(无匹配返回-1)
例如获取test.txt文本中第四行匹配字符串”abc”的下标位置:
1 awk 'NR==4{print index ($0 ,"abc" )}' test .txt
获取test.txt文本中第四行匹配正则表达式”ab[cd]”的下标位置以及RSTART和RLENGTH值
1 awk 'NR==4{print match ($0 ,"ab[cd]" )}' test .txt
awk常用场景 (1)判断进程是否存在,若存在则杀死进程
例如查找nginx进程是否存在:
1 ps -ef | grep "nginx" | grep -v grep | awk 'NR==1{print $2}' | xargs kill -9 >/dev/ null 2 >&1
若能搜索到多个进程ID,去掉NR==1:
1 ps -ef | grep "nginx" | grep -v grep | awk '{print $2}' | xargs kill -9 >/dev/ null 2 >&1
(2)针对输出结果为多行的命令获取指定字段
例如获取当前机器可用内存(M):
1 free -m | awk 'NR==2{print $3 }'
例如获取机器上安装的java版本:
1 java -version 2 >&1 | awk 'NR==1 {gsub(/"/," "); print $3}'
(3)获取当前目录的父目录名
1 pwd | awk -F "/" '{print $NF }'
最后注意点: 1 2 3 4 一、虽然可以通过$0 作用当前行,但awk命令中涉及下标的都是从1 开始 二、awk不会对处理文本的内容做修改 三、所有awk内置方法名均为小写 四、length、sub、gsub三个方法都可以省略最后一个参数,作用于当前行,相当于$0 ,比如length()的输出等同于length($0 )
6.数学函数
函数名
返回值
atan2(x,y)
y,x 范围内的余切
cos(x)
余弦函数
exp(x)
求 幂
int(x)
取整
log(x)
自然对 数
rand()
随机数
sin(x)
正弦
sqrt(x)
平 方根
srand(x)
x是rand()函数的种子
int(x)
取 整,过程没有舍入
rand()
产生一个大于等于0而小于1的随机数
要点:
format格式的指示符都以%开头,后跟一个字符;如下:
修饰符:
8.print print 是awk打印指定内容的主要命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 awk '{print }' /etc/passwd == awk '{print $0} ' /etc/passwd awk '{print " " }' /etc/passwd awk '{print "a" }' /etc/passwd awk -F":" '{print $1} ' /etc/passwd awk -F: '{print $1 ; print $2} ' /etc/passwd awk -F: '{print $1 ,$3 ,$6} ' OFS="\t" /etc/passwd
输出最后一列 1 cat col_print.txt | awk '{print $NF }'
输出整行 1 awk '{print $0 }' col_print.txt
输出倒数第二列 1 cat col_print.txt | awk '{print $(NF-1)} '
输出共有多少列 1 cat col_print.txt | awk '{print NF}'
输出多列 1 cat col_print.txt | awk '{print $2 ,$3 }'
添加自定义字段 1 cat col_print.txt |awk '{ print "第一列:" $1 ,"第二列:" $2 }'
多分隔符的使用: 1 2 awk -F "[/]" 'NR == 4 {print $0 ,"\n " ,$1 }' /etc/passwd #这里以/为分隔符,多个分隔符利用[]然后在里面写分隔符即可
9.pattern 接下来认识下一Pattern,也就是我们所说的模式先介绍AWK 包含两种特殊的模式:BEGIN 和 END。
END 模式指定了处理完所有行之后所需要执行的操作 ;
begin 简单语法 1 awk 'BEGIN { print "BEGIN" }' begin_test
上述例子,虽然指定了begin_test文件作为输入源,但是在开始处理test文本之前,需要先执行BEGIN模式指定的”打印”操作。
不添加输入文件 1 awk 'BEGIN { print "BEGIN" }'
而上面例子中,我们并没有给定任何输入来源,awk就直接输出信息了,因为,BEGIN模式表示,在处理指定的文本之前,需要先执行BEGIN模式中指定的动作,而上述示例没有给定任何输入源,但是awk还是会先执行BEGIN模式指定的”打印”动作,打印完成后,发现并没有文本可以处理,于是就只完成了”打印 BEGIN”的操作。
begin +pattern 演示 1 awk 'BEGIN {print “BEGIN” ,“BEGIN” } { print $1 ,$2 }' col_print.txt
END 可以看到,先处理完BEGIN 的内容,再打印文本里面的内容.
1 2 3 awk 'BEGIN {print "BEGIN"} {print $1} END{ print "END"}' col_print.txt cat /etc/passwd | awk -F: 'BEGIN{print "name, shell"} {print $1,$NF} END{print "hello world"}'
查看最近登录最多的IP信息
1 last | awk '{S[$3]++} END{for(a in S ) {print S[a],a}}' |uniq| sort -rh
利用正则过滤多个空格
1 ifconfig |grep eth* | awk -F '[ ]+' '{print $1 }'
上述示例中返回的结果 就像一张”报表”,有”表头” 、“表内容”、 “表尾”。我们通常将变量初始化语句(如 var=0 )以及打印文件头部的语句放入BEGIN 语句块中。在 END{} 语句块中,往往会放入打印结果等语句.
10.awk编程–变量和赋值 除了awk的内置变量,awk还可以自定义变量, awk中的循环语句同样借鉴于C语言,支持while、do/while、for、break、continue,这些关键字的语义和C语言中的语义完全相同。
统计某个文件夹下的大于100k文件的数量和总和
1 2 3 4 5 6 ls -l|awk '{if($5>100){count++; sum+=$5}} {print "Count:" count,"Sum: " sum}' 【因为awk会轮询统计,所以会显示整个过程】 ls -l|awk '{if($5>100){count++; sum+=$5}} END{print "Count:" count,"Sum: " sum}' 【天界END后只显示最后的结果】 备注:count是自定义变量。之前的action{}里都是只有一个print,其实print只是一个语句,而action{}可以有多个语句,以;号隔开
统计显示/etc/passwd的账户
1 2 3 4 5 awk -F: '{count++;} END{print count}' /etc/passwd cat /etc/passwd|wc -l awk -F ':' 'BEGIN {count=0;} {name[count] = $1;count++;}; END{for (i = 0; i < NR; i++) print i, name[i]}' /etc/passwd
11..-f指定脚本文件 1 2 3 4 5 6 7 8 9 10 11 12 awk -f script.awk file BEGIN{ FS=":" } {print $1} awk 'BEGIN{X=0} /^$/{ X+=1 } END{print "I find" ,X,"blank lines." }' test I find 4 blank lines. ls -l |awk 'BEGIN{sum =0} !/^d /{sum +=$5} END{print "total size is" ,sum }' total size is 17487
12.-F指定分隔符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 $1 指指定分隔符后,第一个字段,$3 第三个字段, \t是制表符一个或多个连续的空格或制表符看做一个定界符,即多个空格看做一个空格 awk -F":" '{print $1} ' /etc/passwd awk -F":" '{print $1 $3} ' /etc/passwd awk -F":" '{print $1 ,$3} ' /etc/passwd awk -F":" '{print $1 " " $3} ' /etc/passwd awk -F":" '{print "Username:" $1 "\t\t Uid:" $3 }' /etc/passwd awk -F: '{print NF}' /etc/passwd awk -F: '{print $NF} ' /etc/passwd awk -F: 'NF==4 {print }' /etc/passwd awk -F: 'NF>2{print $0} ' /etc/passwd awk '{print NR,$0} ' /etc/passwd awk -F: '{print NR,NF,$NF ,"\t" ,$0} ' /etc/passwd awk -F: 'NR==5{print }' /etc/passwd awk -F: 'NR==5 || NR==6{print }' /etc/passwd route -n |awk 'NR!=1{print }' 但是如果我想根据多个分隔符进行分割呢?一种办法是两次awk,但是我们可以一次告诉awk我们所有的分隔符,如-和|这两个,如 awk -F ‘[-|]’ ‘{print $3 ;}’ data 就这么简单,还有一个问题,如果我们想用[]作为分隔符怎么办?有办法,这样就行: awk -F ‘[][]’ ‘{print $3 ;}’ data
13.//匹配代码块 1 2 3 4 5 6 7 8 9 10 11 12 13 // 纯字符匹配 !// 纯字符不匹配 ~// 字段值匹配 !~// 字段值不匹配 ~/a1|a2/ 字段值匹配a1或a2 awk '/mysql/' /etc/ passwd awk '/mysql/{print }' /etc/ passwd awk '/mysql/{print $0}' /etc/ passwd // 三条指令结果一样 awk '!/mysql/{print $0}' /etc/ passwd // 输出不匹配mysql的行 awk '/mysql|mail/{print}' /etc/ passwd awk '!/mysql|mail/{print}' /etc/ passwd awk -F: '/mail/,/mysql/{print}' /etc/ passwd // 区间匹配 awk '/[2][7][7]*/{print $0}' /etc/ passwd // 匹配包含27 为数字开头的行,如27 ,277 ,2777 ... awk -F: '$1~/mail/{print $1}' /etc/ passwd // $1 匹配指定内容才显示 awk -F: '{if($1~/mail/) print $1}' /etc/ passwd // 与上面相同 awk -F: '$1!~/mail/{print $1}' /etc/ passwd // 不匹配 awk -F: '$1!~/mail|mysql/{print $1}' /etc/ passwd
14.IF语句 1 2 3 4 必须用在{}中,且比较内容用()扩起来 awk -F: '{if ($1 ~/mail/) print $1} ' /etc/passwd awk -F: '{if ($1 ~/mail/) {print $1} }' /etc/passwd awk -F: '{if ($1 ~/mail/) {print $1} else {print $2} }' /etc/passwd
15.条件表达式 1 2 3 4 5 6 7 8 == != > >= awk -F":" '$1 =="mysql" {print $3} ' /etc/passwd awk -F":" '{if ($1 =="mysql" ) print $3} ' /etc/passwd awk -F":" '$1 !="mysql" {print $3} ' /etc/passwd awk -F":" '$3 >1000{print $3} ' /etc/passwd awk -F":" '$3 >=100{print $3} ' /etc/passwd awk -F":" '$3 <1{print $3} ' /etc/passwd awk -F":" '$3 <=1{print $3} ' /etc/passwd
16.逻辑运算符 1 2 3 4 5 && || awk -F: '$1 ~/mail/ && $3 >8 {print }' /etc/passwd awk -F: '{if($1 ~/mail/ && $3 >8) print }' /etc/passwd awk -F: '$1 ~/mail/ || $3 >1000 {print }' /etc/passwd awk -F: '{if($1 ~/mail/ || $3 >1000) print }' /etc/passwd
17.数值运算 1 2 3 4 5 6 7 8 awk -F: '$3 > 100' /etc/ passwd awk -F: '$3 > 100 || $3 < 5' /etc/ passwd awk -F: '$3+$4 > 200' /etc/ passwd awk -F: '/mysql|mail/{print $3+10}' /etc/ passwd awk -F: '/mysql/{print $3-$4}' /etc/ passwd awk -F: '/mysql/{print $3*$4}' /etc/ passwd awk '/MemFree/{print $2/1024}' /proc/ meminfo awk '/MemFree/{print int($2/1024)}' /proc/ meminfo
18.指定输入和输出分隔符OFS 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 awk '$6 ~ /FIN/ || NR==1 {print NR,$4 ,$5 ,$6} ' OFS="\t" netstat.txt awk '$6 ~ /WAIT/ || NR==1 {print NR,$4 ,$5 ,$6} ' OFS="\t" netstat.txt 输出处理结果到文件 ①在命令代码块中直接输出 route -n |awk 'NR!=1{print > "./fs" }' ②使用重定向进行输出 route -n |awk 'NR!=1{print }' > ./fs https: --------------- awk默认的分隔符为空格和tab 。然而,实践中往往需要指定其它符号作为分隔符。 输入分隔符 假设有一个test .txt文本文件,其内容如下所示,共4行,每行由逗号分隔成三个元素。现在,通过后续的几种方式对它进行分列操作。 cat test .txtsample1,male,12 sample2,female,23 sample3,male,15 sample4,female,28 1. 第一种方式:通过-F参数实现 通过 -F 参数指定分隔符。需要注意的是,分隔符紧跟在-F参数后面(中间没有空格)。 awk -F, '{print $2} ' test .txt male female male female 2. 第二种方式:通过指定内置变量 FS 来实现 通过-v参数,设置内置变量FS的值为,,从而达到将分隔符指定为逗号。 awk -v FS="," '{print $2} ' test .txt male female male female 输出分隔符 如果拆分的2列或2列以上需要输出,默认也是以空格进行分隔的。例如: awk -v FS=',' '{print $1 ,$3} ' test .txt sample1 12 sample2 23 sample3 15 sample4 28 那么,当需要在输出文件中,需要指定其它分隔符时,可以通过-v 参数指定内置变量OFS实现。例如: awk -v FS="," -v OFS="@@" '{print $1 ,$3} ' test .txt sample1@@12 sample2@@23 sample3@@15 sample4@@28 -F 指定输入文件的的分隔符 -v OFS 指定输出文件的分隔符
19.格式化输出 1 2 3 4 5 6 7 8 9 netstat -anp|awk '{printf "%-8s %-8s %-10s\n " ,$1 ,$2 ,$3 }' printf表示格式输出 %格式化输出分隔符 -8 长度为8 个字符s表示字符串类型 打印每行前三个字段,指定第一个字段输出字符串类型(长度为8 ),第二个字段输出字符串类型(长度为8 ), 第三个字段输出字符串类型(长度为10 ) netstat -anp|awk '$6 =="LISTEN" || NR==1 {printf "%-10s %-10s %-10s \n " ,$1 ,$2 ,$3 }' netstat -anp|awk '$6 =="LISTEN" || NR==1 {printf "%-3s %-10s %-10s %-10s \n " ,NR,$1 ,$2 ,$3 }'
20.IF语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 awk -F: '{if ($3 >100) print "large" ; else print "small" }' /etc/passwd small small small large small small awk -F: 'BEGIN{A=0;B=0} {if ($3 >100) {A++; print "large" } else {B++; print "small" }} END{print A,"\t" ,B}' /etc/passwd awk -F: '{if ($3 <100) next; else print }' /etc/passwd awk -F: 'BEGIN{i=1} {if (i<NF) print NR,NF,i++ }' /etc/passwd awk -F: 'BEGIN{i=1} {if (i<NF) {print NR,NF} i++ }' /etc/passwd 另一种形式 awk -F: '{print ($3 >100 ? "yes" :"no" )}' /etc/passwd awk -F: '{print ($3 >100 ? $3 ":\tyes" :$3 ":\tno" )}' /etc/passwd
while语句
1 2 3 4 5 6 7 awk -F: 'BEGIN{i=1} {while(i<NF) print NF,$i,i++}' /etc/passwd 7 root 1 7 x 2 7 0 3 7 0 4 7 root 5 7 /root 6
21.数组 1 2 3 4 5 6 7 8 9 10 netstat -anp|awk 'NR!=1 {a[$6 ]++} END{for (i in a) print i,"\t " ,a[i]}' netstat -anp|awk 'NR!=1 {a[$6 ]++} END{for (i in a) printf "%-20s %-10s %-5s \n " , i,"\t " ,a[i]}' 9523 1 9929 1 LISTEN 6 7903 1 3038 /cupsd 1 7913 1 10837 1 9833 1
22.应用 输出文件每行有多少字段 1 awk -F: '{print NF}' helloworld.sh
输出前5个字段 1 awk -F: '{print $1 ,$2 ,$3 ,$4 ,$5 }' helloworld.sh
输出前5个字段并使用制表符分隔输出 1 awk -F: '{print $1 ,$2 ,$3 ,$4 ,$5 }' OFS='\t' helloworld.sh
制表符分隔输出前5个字段,并打印行号 1 awk -F: '{print NR,$1 ,$2 ,$3 ,$4 ,$5 }' OFS='\t' helloworld.sh
指定多个分隔符: #,输出每行多少字段 1 awk -F'[:#]' '{print NF}' helloworld.sh
制表符分隔输出多字段 1 awk -F'[:#]' '{print $1 ,$2 ,$3 ,$4 ,$5 ,$6 ,$7 }' OFS='\t' helloworld.sh
指定三个分隔符,并输出每行字段数 1 awk -F'[:#/]' '{print NF}' helloworld.sh
制表符分隔输出多字段 1 awk -F'[:#/]' '{print $1 ,$2 ,$3 ,$4 ,$5 ,$6 ,$7 ,$8 ,$9 ,$10 ,$11 ,$12 }' helloworld.sh
计算/home目录下,普通文件的大小,使用KB作为单位 1 2 ls -l |awk 'BEGIN{sum =0} !/^d /{sum +=$5} END{print "total size is:" ,sum /1024,"KB" }'ls -l |awk 'BEGIN{sum =0} !/^d /{sum +=$5} END{print "total size is:" ,int(sum /1024),"KB" }'
统计netstat -anp 状态为LISTEN和CONNECT的连接数量分别是多少 1 netstat -anp|awk '$6 ~/LISTEN|CONNECTED /{sum [$6 ]++} END{for (i in sum ) printf "%-10s %-6s %-3s \n" , i," " ,sum [i]}'
统计/home目录下不同用户的普通文件的总数是多少? 1 2 3 ls -l|awk 'NR!=1 && !/^d/{sum[$3 ]++} END{for (i in sum) printf "%-6s %-5s %-3s \n " ,i," " ,sum[i]}' mysql 199 root 374
统计/home目录下不同用户的普通文件的大小总size是多少? 1 ls -l|awk 'NR!=1 && !/^d/{sum[$3 ]+=$5 } END{for (i in sum) printf "%-6s %-5s %-3s %-2s \n " ,i," " ,sum[i]/1024 /1024 ,"MB" }'
输出成绩表 1 2 3 4 5 6 7 8 awk 'BEGIN{math=0 ;eng=0 ;com=0 ;printf "Lineno. Name No. Math English Computer Total\n " ;printf "------------------------------------------------------------\n " }{math+=$3 ; eng+=$4 ; com+=$5 ;printf "%-8s %-7s %-7s %-7s %-9s %-10s %-7s \n " ,NR,$1 ,$2 ,$3 ,$4 ,$5 ,$3 +$4 +$5 } END{printf "------------------------------------------------------------\n " ;printf "%-24s %-7s %-9s %-20s \n " ,"Total:" ,math,eng,com;printf "%-24s %-7s %-9s %-20s \n " ,"Avg:" ,math/NR,eng/NR,com/NR}' test0 [root@localhost home]# cat test0 Marry 2143 78 84 77 Jack 2321 66 78 45 Tom 2122 48 77 71 Mike 2537 87 97 95 Bob 2415 40 57 62
例1 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 测试文件test root: x: 0 : 0 :root :/root :/bin/bash bin: x: 1 : 1 :bin :/bin :/bin/false daemon: x: 2 : 2 :daemon :/sbin :/bin/false mail: x: 8 : 12 :mail :/var/spool/mail :/bin/false ftp: x: 14 : 11 :ftp :/home/ftp :/bin/false &nobody: $:99 : 99 :nobody :/ :/bin/false zhangy: x: 1000 : 100 : ,,,:/home/zhangy :/bin/bash http: x: 33 : 33 : :/srv/http :/bin/false dbus: x: 81 : 81 :System message bus: /:/bin/false hal: x: 82 : 82 :HAL daemon: /:/bin/false mysql: x: 89 : 89 : :/var/lib/mysql :/bin/false aaa: x: 1001 : 1001 : :/home/aaa :/bin/bash ba: x: 1002 : 1002 : :/home/zhangy :/bin/bash test: x: 1003 : 1003 : :/home/test :/bin/bash @zhangying:* : 1004 : 1004 : :/home/test :/bin/bash policykit: x: 102 : 1005 :Po 例a cat test | awk -F: '{\ if ($1 == "root"){\ print $1;\ }else if ($1 == "bin"){\ print $2;\ }else {\ print $3;\ } \ }' 例b awk '{\ for (i=0;i<NF;i++){\ if ($i ~/^root/){\ print $i;\ }else if ($i ~/zhangy/){\ print $i;continue;\ }else if ($i ~/mysql/){\ print $i;next ;\ }else if ($i ~/^test/){\ print $i;break ;\ } \ }\ }' test 例c tail test | awk 'BEGIN{while(getline d){ split(d,test);for(i in test){\ print test[i]\ }}}' 例d ls -al /home/zhangy/mytest | awk 'BEGIN {while (getline d){ split(d,test);\ print test[9] ;} }' 例e echo "32:34" | awk -F: '{print "max = ",max($1,$2)}\ function max(one,two){ if(one > two){ return one; }else{ return two; } }' 例f awk -F: '{mat=match($1,/^[a-zA-Z]+$/);print mat,RSTART,RLENGTH}' test 例g cat test |awk -F: '\ NF != 7{\ printf("line %d,does not have 7 fields:%s\n",NR,$0)}\ $1 !~ /^[A-Za-z0-9]/{printf("line %d,non alpha and numeric user id:%s: %s\n",NR,$1,$0)}\ $2 == "*" {printf("lind %d,no password:%s\n",NR,$0)}'
例2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 测试文件 [root@ Blackghost test2]# cat aaa 1111 :23434 :zhanghoadsf:asdf:ccc [root@ Blackghost test2]# cat ccc 1111 :23434 :zhanghoadsf:asdf:ccc tank:zhang:x20342 ying:zhasdf:72342 hosa:asdfa:2345 sdf 例a [root@ Blackghost test2]# awk '{print NR;print FNR;print $0;}' aaa 1 1 1111 :23434 :zhang2 2 hoadsf:asdf:ccc 例b [root@ Blackghost test2]# awk '{print NR;print FNR;print $0;}' aaa ccc 1 1 1111 :23434 :zhang2 2 hoadsf:asdf:ccc 3 1 1111 :23434 :zhang4 2 hoadsf:asdf:ccc 5 3 tank:zhang:x20342 6 4 ying:zhasdf:72342 7 5 hosa:asdfa:2345 sdf
例3 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 59314 46791 59992 60311 60134 59992 60311 97343 59314 46791 59992 60311 60134 97343
获取本机上网络接口上可用的公网IP地址 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 处理前: [root@ practice ~]# ip addr show 1 : lo: mtu 16436 qdisc noqueue link/loopback 00 :00 :00 :00 :00 :00 brd 00 :00 :00 :00 :00 :00 inet 127.0 .0 .1 /8 scope host lo inet 10.99 .133 .33 /32 scope global lo 2 : eth2: mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 0 :1 b:21 :48 :3 e:b3 brd ff:ff:ff:ff:ff:ff inet 172.20 .33 .44 /23 brd 172.20 .33 .255 scope global eth2 3 : eth3: mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00 :1 b:31 :39 :3 e:2 c brd ff:ff:ff:ff:ff:ff 4 : eth0: mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00 :25 :29 :09 :8 e:f2 brd ff:ff:ff:ff:ff:ff inet 228.215 .154 .140 /26 brd 228.215 .154 .191 scope global eth0 5 : eth1: mtu 1500 qdisc pfifo_fast qlen 1000 link/ether 00 :25 :09 :09 :8 e:f3 brd ff:ff:ff:ff:ff:ff inet 228.215 .154 .150 /26 brd228.215 .154 .191 scope global eth1 处理后 [root@ practice ~]# ip addr show | awk 'BEGIN{FS="[/ ]+";OFS=" -- "}$2~"eth"{$3~"NO-CARRIER"?a=0:a=1}$NF~"eth"&&a{print $NF,$3}' eth0 -- 228.215 .154 .140 eth1 -- 228.215 .154 .150 获取本机上网络接口上可用的公网IP地址 BEGIN{FS="[/ ]+" ;OFS=" -- " } 是指把一个或多个空格或者/作为读取文本时的字段分隔符,把" -- " 作为执行完后的输出字段分隔符 $2 ~"eth" {$3 ~"NO-CARRIER" ?a=0 :a=1 }找到第二个字段匹配到"eth" 的行并判断第三个字段是否匹配到"NO-CARRIER" ,匹配到则a=0 ,否则a=1 $NF~"eth" &&a将最后一个字段和a相与,结果为真则打印最后一个字段和第三个字段,否则不处理
awk取出last命令结果中非空行 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 [root@practice ~]# last |awk '$0 !="" &&$2 !~"boot" &&$3 ~"[[:digit:]]" {ips[$3 ]++}END{for(i in ips)printf "%18-s%10-d\n " ,i,ips[i]}' 172.20 .33 .1 1 172.20 .33 .95 7 192.168 .2 .100 6 192.168 .2 .101 3 172.20 .33 .26 1 192.168 .2 .102 8 172.20 .32 .123 7 192.168 .140 .1 2 172.20 .33 .93 1 &&表示 且,与 $0 !="" 表示排除结果中的空行 $2 !~"boot" 表示排除重启的记录 $3 ~"[[:digit:]]表示第三个字段匹配数字而不是字符 {ips[$3]++}表示把第三个字段即IP地址作为下标,组成一个数组ips,IP地址每出现一次,其出现次数累加一 END{for(i in ips)printf " %18 -s%10 -d\n",i,ips[i]} 表示从数组中获取每个IP地址,及其出现的次数,并定义对齐方式和变量类型打印出来
将passwd中的第三列放到test中 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #将passwd中的第三列放到test中 [root@ localhost ~]# awk -F: '{if(NR>=10 && NR<=20) print $3 }' /etc/passwd > test You have mail in /var/spool/mail/root [root@ localhost ~]# cat test 10 11 12 13 14 99 81 113 69 32 499
例4 1 2 3 4 5 6 7 8 9 10 11 12 [root@ xuegod68 mnt]# head -5 2. txt 10.0 .0 .3 --[21 /Mar/2015 -07 :50 :17 +0800 ]*GET/HTTP/1.1 *200 19 *-*10.0 .0 .3 --[21 /Mar/2015 -07 :50 :17 +0800 ]*GET/HTTP/1.1 *200 19 *-*10.0 .0 .5 --[21 /Mar/2015 -07 :50 :17 +0800 ]*GET/HTTP/1.1 *200 19 *-*10.0 .0 .3 --[21 /Mar/2015 -07 :50 :17 +0800 ]*GET/HTTP/1.1 *200 19 *-*10.0 .0 .6 --[21 /Mar/2015 -07 :50 :17 +0800 ]*GET/HTTP/1.1 *200 19 *-*[root@ xuegod68 mnt]# awk '{array[$1]++} END {for(key in array) printkey,array[key]}' 2. txt 10.0 .0 .3 35 10.0 .0 .4 5 10.0 .0 .5 10 10.0 .0 .6 10
将UID大于等于500的用户及UID打印出来 1 2 3 4 [root@localhost ~]# awk -F: '$3>=500 {print $1,$3}' /etc/passwd nfsnobody 65534 admin 502 test 503
打包当前目录下的所有文件 1 ls | awk '{ print "tar zcvf " $0 ".tar.gz " $0 |"/bin/bash" }'
取范围 1 2 3 4 [root@VM -202 zhuo]# echo "abc#1233+232@jjjj?===" |awk -F '[#@]' '{print $2}' 1233 +232 [root@VM -202 zhuo]# echo "abc#1233+232@jjjj?===" |awk -F '[@?]' '{print $2}' jjjj
匹配非空行 1 awk '/^[^$]/ {print $0 }' test.txt
匹配非包含zhuo的 1 awk '/^[^zhuo]/ {print $0 }' test.txt
替换(将:替换成#) 1 2 [root@VM-202 zhuo]# echo "zhuo:x:503:504::/home/zhuo:/bin/bash" |awk 'gsub(/:/,"#") {print $0}' zhuo#x#503 #504 ##/home/zhuo#/bin/bash
列求和、平均值、最大值、最小值 1 2 3 4 5 6 7 8 9 10 11 you.txt文档内容 1 2 3 4 列求和: cat you.txt |awk 列求平均值:cat you.txt |awk 列求最大值:cat you.txt |awk 设定一个变量开始为0 ,遇到比该数大的值,就赋值给该变量,直到结束。 求最小值:cat you.txt |awk
求全文的最值 1 2 3 4 5 6 7 8 9 10 求全文的最值 例:求test.txt的最值 12 34 56 78 24 65 87 90 76 11 67 87 100 89 78 99 for i in `cat test.txt` ;do echo $i; done |sort |sed -n '1 p;2 p' 例2 :同样是test.txt 求总和:for i in `cat you.txt`;do echo $i ;done |awk '{a+=$1 }END{print a}'
例5 1 2 3 4 5 6 7 8 9 10 11 12 例3 : A 88 B 78 B 89 C 44 A 98 C 433 要求输出:A:88 ;98 B:78 ;89 C:44 ;433 awk '{a[$1 ]=a[$1 ]" " $2 }END{for(i in a)print i,a[i]}' test.txt |awk '{print $1 ":" ,$2 ";" ,$3 }'
使用awk进行数字计算,保留指定位小数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 [root@block-storage09 stap] 0 .85 [wangdong@centos715-node1 ~]$ echo | awk '{print 1.5*3}' 4.5 看上去还可以,那么进一步,我需要带变量: [wangdong@centos715-node1 ~]$ A=5 [wangdong@centos715-node1 ~]$ B=16 [wangdong@centos715-node1 ~]$ C=29 [wangdong@centos715-node1 ~]$ echo | awk '{print $A/$B}' awk: cmd. line:1 : (FILENAME=- FNR=1 ) fatal: division by zero attempted [wangdong@centos715-node1 ~]$ echo | awk "{print $A/$B}" 0 .3125 [wangdong@centos715-node1 ~]$ echo | awk "{print $C*$A}" 145 [wangdong@centos715-node1 ~]$ echo | awk "{print $C*$A/$B}" 9.0625 看上去也还可以,只是注意awk后的单引号需要变为双引号。 再进一步,上面最后一次的计算,小数点后面出现了4 位,我希望只保留两位,不然看着太乱。但是没有找到这里可以保留小数位的参数和方法,于是我尝试一下将print 换为printf : [wangdong@centos715-node1 ~]$ echo | awk '{print 10/3}' 3.33333 [wangdong@centos715-node1 ~]$ echo | awk '{printf ("%.2f\n",10/3)}' 3.33 将print 换成printf ,就可以有方法进行小数位的限制了,看似不错,但是…… [wangdong@centos715-node1 ~]$ A=5 [wangdong@centos715-node1 ~]$ B=16 [wangdong@centos715-node1 ~]$ C=29 [wangdong@centos715-node1 ~]$ echo | awk '{printf ("%.2f\n",$A/$B)}' awk: cmd. line:1 : (FILENAME=- FNR=1 ) fatal: division by zero attempted [wangdong@centos715-node1 ~]$ echo | awk "{printf (" %.2 f\n",$A/$B)}" awk: cmd. line:1 : {printf (%.2 fn,5 /16 )} awk: cmd. line:1 : ^ syntax error [wangdong@centos715-node1 ~]$ echo | awk "{printf ('%.2f\n',$A/$B)}" awk: cmd. line:1 : {printf ('%.2f\n' ,5 /16 )} awk: cmd. line:1 : ^ invalid char '' ' in expression awk: cmd. line:1: {printf (' %.2 f\n',5/16)} awk: cmd. line:1: ^ syntax error 使用变量参与计算的话,会发现一直在报错,这种情况,建议先在前面的echo中将需要使用的变量输出出来,再进行调用。 [wangdong@centos715-node1 ~]$ A=5 [wangdong@centos715-node1 ~]$ B=16 [wangdong@centos715-node1 ~]$ C=29 [wangdong@centos715-node1 ~]$ D=6 [wangdong@centos715-node1 ~]$ echo "$A $B $C $D" | awk ' {printf ("%.2f\n" ,$1*$2/$3-$4)}' -3.24 [wangdong@centos715-node1 ~]$ echo "$A $B $C $D" | awk ' {printf ("%.2f\n" ,$1/$4)}' 0.83 [wangdong@centos715-node1 ~]$ echo "$A $B $C $D" | awk ' {printf ("%.3f\n" ,$1/$4)}' 0.833 注意,使用printf的时候,awk后面必须是单引号,双引号会报错。虽然这种方法麻烦一些,但是起码可以实现我的需求,如果有朋友知道bc计算的结果为0-1之间的小数时,怎么让他显示出来前面的0. ,欢迎留言,不喜勿喷。 补充,有的时候在计算数字后,会发现你的结果已经不是正常的一串数字了,而是在其中穿插了字母e或者E,这是因为数字过大,系统采用了类似于科学计数法的表达方式(正确叫法不确定,勿喷),但是如果直接使用这一串内容再去计算的话,会报错,系统会认为这是字符串而非数字,这种情况也可以使用awk进行转变,其实准确的说是printf的功能。 [wangdong@centos715-node1 uncomp]$ echo "6.8923e+08/100" |bc (standard_in) 1: syntax error [wangdong@centos715-node1 uncomp]$ echo "6.8923e+08" | awk ' {printf ("%.0f\n" ,$1)}' 689230000
其它数字计算方法 1、bc bc应该是最常用的Linux中计算器了,简单方便,支持浮点。
1 2 3 4 5 6 7 8 [wangdong@ centos715-node1 ~]$ echo 1 +2 |bc 3 [wangdong@ centos715-node1 ~]$ echo 5.5 *3.3 |bc 18.1 [wangdong@ centos715-node1 ~]$ echo 5 /3 |bc 1 [wangdong@ centos715-node1 ~]$ echo "scale=2;5/3" |bc 1.66
看似在简单计算时候完美的bc,其实也有一个让我抓狂的地方,当然有可能有办法可以解决,只是我不知道而已,那就是…… 在出现整数部分为0的时候,这个0是不显示出来的,例如0.5只会显示为.5,情何以堪!
1 2 3 4 [wangdong@centos715 -node1 ~]$ echo "scale=2;1/2" |bc .50 [wangdong@centos715 -node1 ~]$ echo "scale=4;17/20" |bc .8500
而且…… 像一些第三方基于Linux底层的产品,为了系统本身的稳定和轻便,默认是不带bc的,例如……F5
2、expr 不支持浮点计算,即不支持小数,所以也常被用来判断变量内容或者结果是不是非0整数(expr 0的echo $?不是0)。
1 2 3 4 5 6 7 8 9 10 11 12 13 [wangdong@ centos715-node1 ~]$ expr 3 + 5 8 [wangdong@ centos715-node1 ~]$ expr 10 / 2 5 [wangdong@ centos715-node1 ~]$ expr 10 / 3 3 [wangdong@ centos715-node1 ~]$ expr 7 / 2 3 [wangdong@ centos715-node1 ~]$ expr 0 0 [wangdong@ centos715-node1 ~]$ echo $? 1 3 、$(())
不支持浮点计算。
1 2 3 4 5 6 7 8 [wangdong@ centos715-node1 ~]$ echo $((8 +3 )) 11 [wangdong@ centos715-node1 ~]$ echo $((10 /2 )) 5 [wangdong@ centos715-node1 ~]$ echo $((10 /3 )) 3 [wangdong@ centos715-node1 ~]$ echo $((1.5 *3 )) -bash: 1.5 *3 : 语法错误: 无效的算术运算符 (错误符号是 ".5*3" )
4、let 不仅不支持浮点计算,而且还只能赋值,不能直接输出。
1 2 3 4 5 6 7 8 9 10 [wangdong@ centos715-node1 ~]$ let a=1 +2 [wangdong@ centos715-node1 ~]$ echo $a 3 [wangdong@ centos715-node1 ~]$ let b=10 /5 [wangdong@ centos715-node1 ~]$ echo $b 2 [wangdong@ centos715-node1 ~]$ let c=1.5 *3 -bash: let: c=1.5 *3 : 语法错误: 无效的算术运算符 (错误符号是 ".5*3" ) [wangdong@ centos715-node1 ~]$ echo $c [wangdong@ centos715-node1 ~]$
上面的几种方式,是我之前常用的方式,但是现在我在shell脚本中有一个需求,在计算数字时,会出现浮点计算,也会出现0-1之间的小数,前面的几个方式恐怕都无法满足。
引用:https://www.cnblogs.com/ftl1012/p/9250541.html https://www.cnblogs.com/xudong-bupt/p/3721210.html https://www.cnblogs.com/jackhub/p/3549091.html http://www.mamicode.com/info-detail-1187091.html